Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund
Schema
Alrighty – so you have been learning about the Semantic Engine and how important documentation is when it comes to research data – ok, ok, yes documentation is important to any and all data, but we’ll stay in our lanes here and keep our conversation to research data. We’ve talked about Research Data Management and how the FAIR principles intertwine and how the Semantic Engine is one fabulous tool to enable our researchers to create FAIR research data.
But… now that you’ve created your data schema, where can you save it and make it available for others to see and use? There’s nothing wrong with storing it within your research group environment, but what if there are others around the world working on a related project? Wouldn’t it be great to share your data schemas? Maybe get a little extra reference credit along your academic path?
Let me walk you through what we have been doing with the data schemas created for the Ontario Dairy Research Centre data portal. There are 30+ data schemas that reflect the many data sources/datasets that are collected dynamically at the Ontario Research Dairy Centre (ODRC), and we want to ensure that the information regarding our data collection and data sources is widely available to our users and beyond by depositing our data schemas into a data repository. We want to encourage the use and reuse of our data schemas – can we say R in FAIR?
Storing the ADC data schemas
Agri-food Data Canada(ADC) supports, encourages, and enables the use of national platforms such as Borealis – Canadian Dataverse Repository. The ADC team has been working with local researchers to deposit their research data into this repository for many years through our OAC Historical Data project. As we work on developing FAIR data and ensuring our data resources are available in a national data repository, we began to investigate the use of Borealis as a repository for ADC data schemas. We recognize the need to share data schemas and encourage all to do so – data repositories are not just for data – let’s publish our data schemas!
If you are interested in publishing your data schemas, please contact adc@uoguelph.ca for more information. Our YouTube series: Agri-food Data Canada – Data Deposits into Borealis (Agri-environmental Data Repository) will be updated this semester to provide you guidance on recommended practices on publishing data schemas.
Where is the data schema?
So, I hope you understand now that we can deposit data schemas into a data repository – and here at ADC, we are using the Borealis research data repository. But now the question becomes – how, in the world do I find the data schemas? I’ll walk you through an example to help you find data schemas that we have created and deposited for the data collected at the ODRC.
- Visit Borealis (the Canadian Dataverse Repository) or the data repository for research data.
- In the search box type: Milking data schema
- You will get a LOT of results (152, 870+) so let’s try that one again
- Go back to the Search box and using boolean searching techniques in the search box type: “data schema” AND milking
- Now you should have around 35 results – essentially any entry that has the words data schema together and milking somewhere in the record
- From this list select the entry that matches the data you are aiming to collect – let’s say the students were working with the cows in the milking parlour. So you would select ODRC data schema: Milk parlour data


Now you have a data schema that you can use and share among your colleagues, classmates, labmates, researchers, etc…..
Remember to check out what you else you can do with these schemas by reading about all about Data Verification.
Summary
A quick summary:
- I can deposit my data schemas into a repository – safe keeping, sharing, and getting academic credit all in one shot!
- I can search for a data schema in a repository such as Borealis
- I can use a data schema someone else has created for my own data entry and data verification!
Wow! Research data life is getting FAIRer by the day!
![]()
What do you do when you’ve collected data but you need to also include notes in the data. Do you mix the data together with the notes?
Here we build on our previous blog post describing data quality comments with worked examples.
An example of quality comments embedded into numeric data is if you include values such as NULL or NA when you have a data table. Below are some examples of datatypes being assigned to different attributes (variables v1-v8). You can see in v5 that there is are numeric measurements values mixed together with quality notations such as NULL, NA, or BDL (below detection limit).
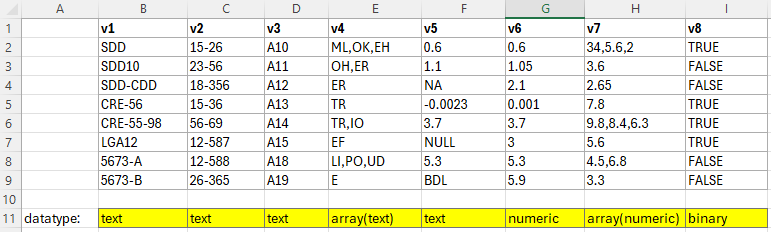
Technically, this type of data would be given the datatype of text when using the Semantic Engine. However, you may wish to use v5 as a numeric datatype so that you can perform analysis with it. You could delete all the text values, but then you would be losing this important data quality information.
As we described in a previous blog post, one solution to this challenge is to add quality comments to your dataset. How you would do this is demonstrated in the next data example.
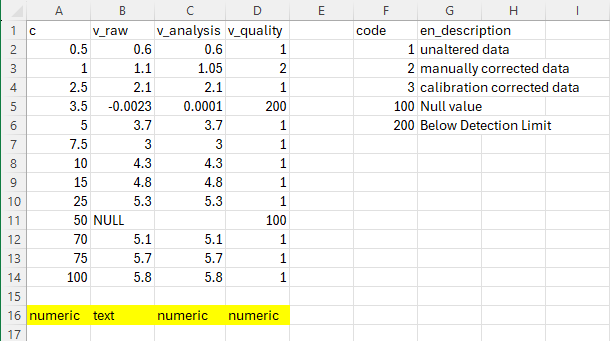
In this next example there are two variables: c and v. Variable v contains a mixture of numeric values and text.
step 1: Rename v to v_raw. It is good practice to always keep raw data in its original state.
step 2: copy the values into v_analysis and here you can remove any text values and make other adjustments to values.
step 3: document your adjustments in a new column called v_quality and using a quality code table.
The quality code table is noted on the right of the data. When using the Semantic Engine you would put this in a separate .csv file and import it as an entry code list. You would also remove the highlighted dataypes (numeric, text etc.) which don’t belong in the dataset but are written here to make it easier to understand.
You can watch the entire example being worked through using the Semantic Engine in this YouTube video. Note that even without using the Semantic Engine you can annotate data with quality comments, the Semantic Engine just makes the process easier.
Written by Carly Huitema
There is a new feature just released in the Semantic Engine!
Now, after you have written your schema you can use this schema to enter and verify data using your web browser.
Find the link to the new tool in the Quick Link lists, after you have uploaded a schema. Watch our video tutorial on how to easily create your own schema.

Add data
The Data Entry Web tool lets you upload your schema and then you can optionally upload a dataset. If you choose to upload a dataset, remember that Agri-food Data Canada and the Semantic Engine tool never receive your data. Instead, your data is ‘uploaded’ into your browser and all the data processing happens locally.
If you don’t want to upload a dataset, you can skip this step and go right to the end where you can enter and verify your data in the web browser. You add rows of blank data using the ‘Add rows’ button at the bottom and then enter the data. You can hover over the ?’s to see what data is expected, or click on the ‘verification rules’ to see the schema again to help you enter your data.
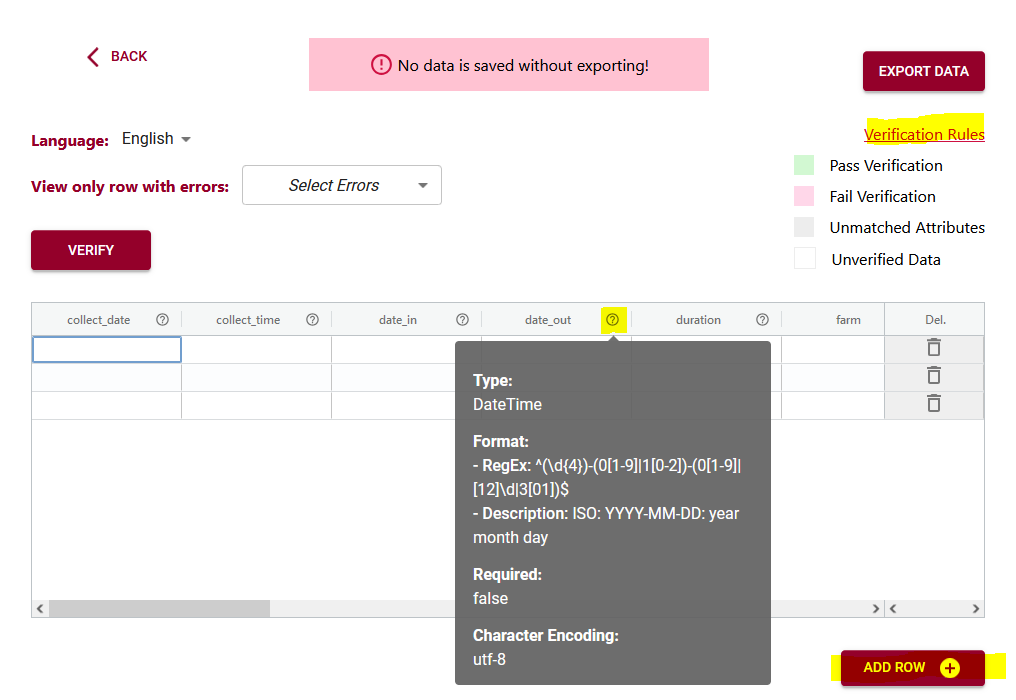
If you upload your dataset you will be able to use the ‘match attributes’ feature. If your schema and your dataset use the same column headers (aka variables or attributes), then the DEW tool will automatically match those columns with the corresponding schema attributes. Your list of unmatched data column headers are listed in the unassigned variables box to help you identify what is still available to be matched. You can create a match by selecting the correct column name in the associated drop-down. By selecting the column name you can unmatch an assigned match.
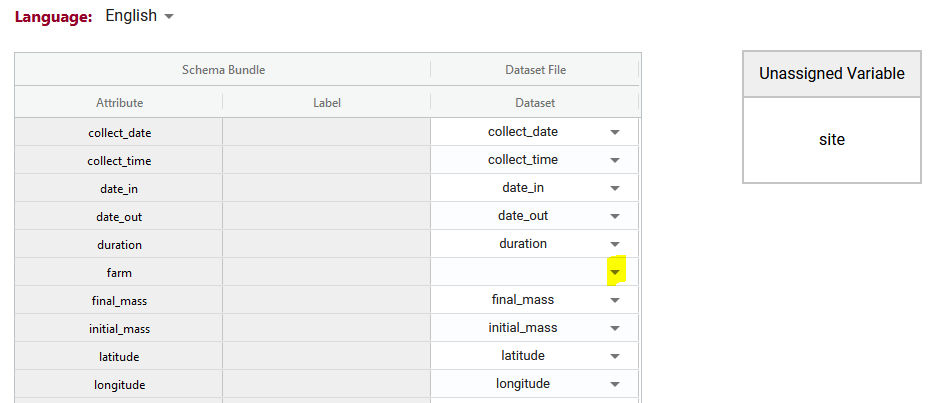
Matching data does two things:
1) Lets you verify the data in a data column (aka variable or attribute) against the rules of the schema. No matching, no verification.
2) When you export data from the DEW tool you have the option of renaming your column names to the schema name. This will automate future matching attempts and can also help you harmonize your dataset to the schema. No matching, no renaming.
Verify data
After you have either entered or ‘uploaded’ data, it is time to use one of the important tools of DEW – the verification tool! (read our blog post about why it is verification and not validation).
Verification works by comparing the data you have entered against the rules of the schema. It can only verify against the schema rules so if the rule isn’t documented or described correctly in the schema it won’t verify correctly either. You can always schedule a consultation with ADC to receive one-on-one help with writing your schema.
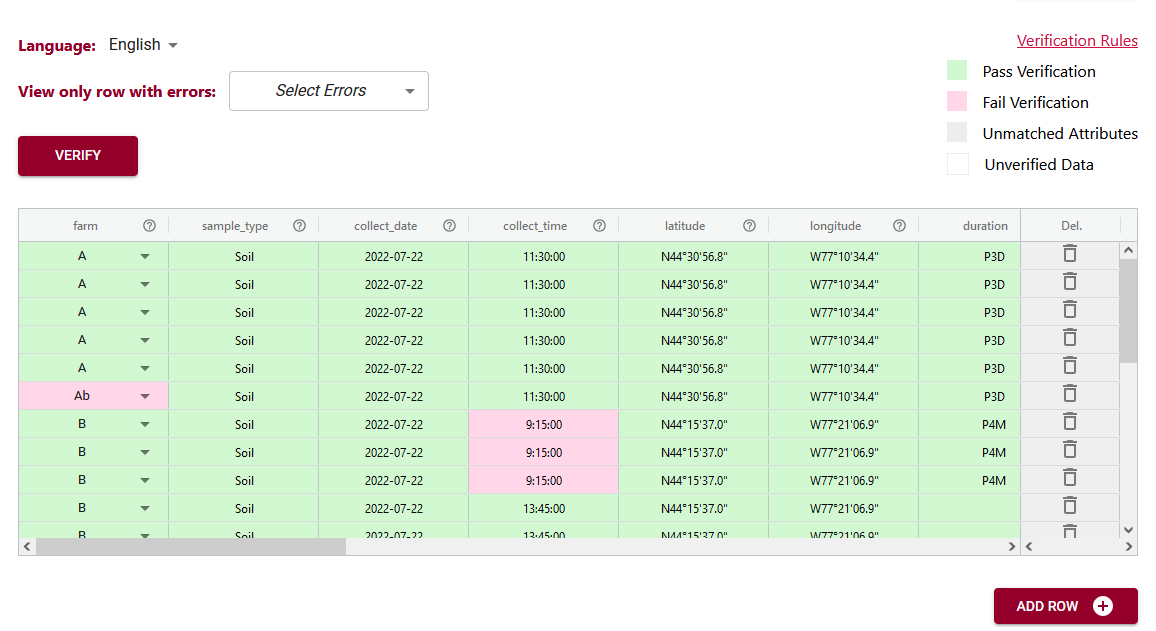
In the above example you can see the first variable/attribute/column is called farm and the DEW tool displays it as a list to select items from. In your schema you would set this feature up by making an attribute a list (aka entry codes). The other errors we can see in this table are the times. When looking up the schema rules (either via the link to verification rules which pops up the schema for reference, or by hovering over the column’s ?) you can see the expected time should be in ISO standard (HH:MM:SS), which means two digits for hour. The correct times would be something like 09:15:00. These format rules and more are available as the format overlay in the Semantic Engine when writing your schema. See the figure below for an example of adding a format rule to a schema using the Semantic Engine.

Export data
A key thing to remember, because ADC and the Semantic Engine don’t ever store your data, if you leave the webpage, you lose the data! After you have done all the hard work of fixing your data you will want to export the data to keep your results.
You have a few choices when you export the data. If you export to .csv you have the option of keeping your original data headers or changing your headers to the matched schema attributes. When you export to Excel you will generate an Excel following our Data Entry Excel template. The first sheet will contain all the schema documentation and then next sheet will contain your data with the matching schema attribute names.
The new Data Entry Web tool of the Semantic Engine can help you enter and verify your data. Reuse your schema and improve your data quality using these tools available at the the Semantic Engine.
Written by Carly Huitema
When submitting a publication to a journal you are often asked to submit data, publish it in a repository, or otherwise make it available. The journals may ask that your data supports FAIR principles (that data is Findable, Accessible, Interoperable and Reusable). You may be asked to submit supplementary data to a generalist or specialist repository, or you may choose to make the data available on request.
More FAIR data
Writing schemas to document your data using the Semantic Engine can help you meet these journal submission goals and requirements. The information documented in a schema (which may also be described as the data dictionary or the dataset metadata) helps your research data be more FAIR.
Documented information makes the data more findable in searches, accessible because people know what is in your datasets and can understand it, interoperable because people don’t need to guess what your data means, what your units are, and how you measured certain variables. All these contribute to improve the reusability of your dataset.
Deposit a schema
When you submit a dataset in any repository you can include the schemas (both the machine-readable .zip/JSON version and the human-readable and archival Readme.txt version) in your submission.
If you only want to make your data available by request you could publish just your schema, giving it a DOI, and referencing it in your publication. This way, anyone who wants to know if your data is useful before requesting it can look at the schema to see if it could contain information that they need.
The Semantic Engine makes it easy to document your schema because it is an easy to follow web interface with prompts and help information which assist you in writing your data schema. Follow our tutorial video to see how easy it is to create your own schema. You can use this documentation when submitting your data to a journal publication so that other people can understand and benefit from your data.
Written by Carly Huitema
When you create a schema using the Semantic Engine you are documenting information that can make your dataset more FAIR, helping others use and understand your data. The schema created using the Semantic Engine is understood by machines and is written in JSON. At first glance, it is not so easy for people to read JSON which is where the readme.txt file version comes to help. All information of the schema bundle is copied into the readme.txt along with some extra helping information. To support long-term archiving it is important to document using low requirement data formats which is why the plain-text format has been selected for a human-readable, archive ready version of your schema written using the Semantic Engine.
The readme text file begins with reference material. This reference material is the same for every OCA schema readme.txt. At the top it gives the version number of the readme (1.0 in this example), provides citations of where the information is coming from, and gives a short introduction to what a schema is.
BEGIN_REFERENCE_MATERIAL ****************************************************************** OCA_READ_ME/1.0 This is a human-readable schema, based on the OCA schema standard. Reference for Overlays Capture Architecture (OCA): https://doi.org/10.5281/zenodo.7707467 Reference for OCA_READ_ME/1.0: https://github.com/agrifooddatacanada/OCA_README A schema describes details about a dataset. In OCA, a schema consists of a capture_base which documents the attributes and their most basic features. A schema may also contain overlays which add details to the capture_base. For each overlay and capture_base, a hash of their original contents has been calculated and is reported here as the SAID value. This README format documents the capture_base and overlays that were associated together in a single OCA Bundle. OCA_MANIFEST lists all components of the OCA Bundle. For the OCA_BUNDLE, each section between rows of ****'s contains the details of one "layer type/version" of the OCA Bundle. ****************************************************************** END_REFERENCE_MATERIAL
After the reference material we list the manifest – the contents of schema listed overlay by overlay along with their digest identifiers. The digest identifiers are calculated from the contents of the schema components and are written here to help with reproducibility.
BEGIN_OCA_MANIFEST ********************************************************************** Bundle SAID/digest: unavailable capture_base SAID/digest: ElQVB8ffr4TdvPvCgxmHjZxhUR_JcPkuLRpuHY1oU7HA, character_encoding SAID/digest: EKwa4p3qiRjizl-bhiVy-sC5jd8FzNLyhL842vbEGpXM, conformance SAID/digest: ECj97Q3zZQYLyuyHli2x7rLvLaPKmpKkurPnnPMD9wbY, entry (en) SAID/digest: EIbRDpClXxWw202M3D5sTYPq5G4ZnLEta8FvK9lclunQ, entry_code SAID/digest: E6AuDvomYlHQ6k9HMRUCRYQnkESaGPZzh17CkVgsltPo, format SAID/digest: EDozfjgDRT3YzWoGo23E2VYt-Nh4iepYMc3kf02Uh1u4, information (en) SAID/digest: EU-VGxKVUPBqBPqdQvi_pdLBduJvFIjrQJZHKHlBsAvM, label (en) SAID/digest: EgOwKdgjdcEP5y0l8Nx8RmpU74GKB-opBZj7LF-Y1hFc, meta (en) SAID/digest: EUmhlW5XLF7GtyZeToaaP0XNcaOKD61s_48bFCX6J-sw, unit SAID/digest: "EaN1jMNQamXdPTRm-CB4Si5Oj6kt3xjmE2BjXkOzT664" ********************************************************************** END_OCA_MANIFEST
Next comes the components of the schema bundle where each component is separated by a row of *’s. Each layer is described with a name and version (e.g. capture_base layer version 1.0) and the SAID reproduced from the manifest.
In this section, the capture_base is documented with the the schema classification (RDF402) and any attributes marked as sensitive (animal_id). After that comes a list of all the attributes (variables) in the schema along with the attribute’s datatype.
BEGIN_OCA_BUNDLE ********************************************************************** Layer name: capture_base/1.0 SAID/digest: ElQVB8ffr4TdvPvCgxmHjZxhUR_JcPkuLRpuHY1oU7HA classification: RDF402 flagged_attributes: [animal_id] Schema attribute: data type animal_id: Numeric begin_time: DateTime date: DateTime dim: Numeric duration: DateTime end_date: DateTime end_time: DateTime lact_n: Numeric milking_location: Text session_n: Numeric total_yield: Numeric
Each overlay of the schema bundle is documented in the readme.txt file. For example here is the format overlay (version 1.0) listed each attribute and the format feature for each attribute (written in Regular Expressions).
********************************************************************** Layer name: format/1.0 SAID/digest: EDozfjgDRT3YzWoGo23E2VYt-Nh4iepYMc3kf02Uh1u4 Schema attribute: format/1.0 animal_id: ^-?[0-9]+$ begin_time: ^([01][0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]$/gm date: ^(?:(?:19|20)\\d2)-(?:0[1-9]|1[0-2])-(?:0[1-9]|[1-2]\\d|3[0-1])$ dim: ^-?[0-9]+$ duration: ^([01][0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]$/gm end_date: ^(?:(?:19|20)\\d2)-(?:0[1-9]|1[0-2])-(?:0[1-9]|[1-2]\\d|3[0-1])$ end_time: ^([01][0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]$/gm lact_n: ^-?[0-9]+$ milking_location: ^.050$ session_n: ^-?[0-9]+$ total_yield: ^[-+]?\\d*\\.?\\d+$
One by one, each overlay is described until the end of the schema bundle. The readme.txt file can be renamed to whatever is suitable for your dataset and can be stored as a human-readable and archival version of your schema to accompany your machine-readable JSON version of a schema.
Written by Carly Huitema
At the Semantic Engine we have created a new video example where we walk through the process of describing a dataset with a schema. We are using a dataset with milking data that has been downloaded from the research dairy barn.
You can watch the video on YouTube or follow along in the schema writing tutorial, and then go to the Semantic Engine and write your own dataset schema.
The video covers several tips and tricks that have been discussed here in our blog including:
Importing Entry Codes from another schema
Using ISO standards for dates and times
Written by Carly Huitema
The Semantic Engine has a new upgrade for importing existing entry codes!
If you don’t know what entry codes are, you can check out our blog post about how to use entry codes. We also walk through an example of entry codes in our video tutorial.
While you can type your entry codes and labels in directly when writing your schema, if you have a lot of entry codes it might be easier to import them. We already discussed how to import entry codes from a .csv file, or copy them from another attribute, but you can also import them from another OCA schema. You use the same process for uploading the schema bundle as you would for the .csv file.
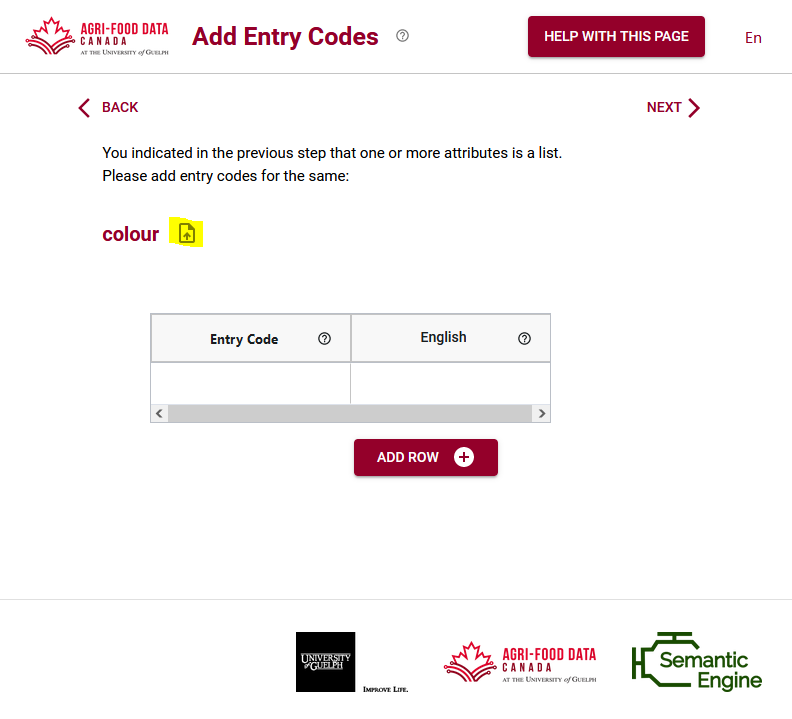
The advantage of using entry codes from an existing schema is that you can reuse work that someone has already done. If you like their choice of entry codes now your schema can also include them. After importing a list of entry codes you can extend the list by adding more codes as needed.
You can watch an example of entry codes in action in our tutorial video.
Entry codes are very valuable and can really help with your data standardization. The Semantic Engine can help you add them to your data schemas.
Written by Carly Huitema
In Overlays Capture Architecture (OCA), when using the Semantic Engine you must assign data types to all of your attributes (aka variables). When do you use the array datatype?
You use an array data type when a data record for that attribute would hold multiple values of a specific data type, arranged in a list-like structure. Multiple values is the key. If you perform a measurement, and you record that single value in your data set, that attribute datatype is not an array of values; it is a single value.
However, if you collect multiple measurements, arrange them into a list using a separator to separate each value, and store that list of values in your dataset in a single record for a single attribute (e.g. in a single Excel cell where each value is separated by a comma), then you have an array.
Array data type example
Here are two examples. The table on the left does not have an array data type (it is datatype=numeric) whereas the table on the right contains an array data type (specifically array[numeric]) and uses a comma separator.
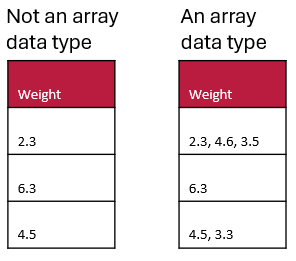
Array data types may be especially useful in questionnaires when you can allow multiple selections for a question (e.g. asking the user to select all the options that apply).
Here are the key characteristics and examples of when you would categorize a data type as an array data type:
- Multiple Elements: An array can store multiple values.
- Same Data Type: All elements in an array must be of the same data type (e.g., all numeric, all strings).
- Indexed Access: Elements in an array can be accessed via their index positions.
In summary, you categorize a data type as an array when it is explicitly defined to contain a collection of elements of the same type, accessible via indices, and useful for storing lists, collections, or sequences of values.
Written by Carly Huitema
Is your data ready to describe using a schema? How can you ensure the fewest hiccups when writing your schema (such as with the Semantic Engine)? What kind of data should you document in your schema and what kinds of data can be left out?
Document data in chunks
When you prepare to describe your data with a schema, try to ensure that you are documenting ‘data chunks’, which can be grouped together based on function. Raw data is a type of data ‘chunk’ that deserves its own schema. If you calculate or manipulate data for presentation in a figure or as a published table you could describe this using a separate schema.
For example, if you take averages of values and put them in a new column and calculate this as a background signal which you then remove from your measurements which you put in another column; this is an summarizing/analyzing process and is probably a different kind of data ‘chunk’. You should document all the data columns before this analysis in your schema and have a separate table (e.g. in a separate Excel sheet) with a separate schema for manipulated data. Examples of data ‘chunks’ include ‘raw data’, ‘analysis data’, ‘summary data’ and ‘figure and table data’. You can also look to the TIER protocol for how to organize chunks of data through your analysis procedures.
Look for Entry Code opportunities
Entry codes can help you streamline your data entry and improve existing data quality.
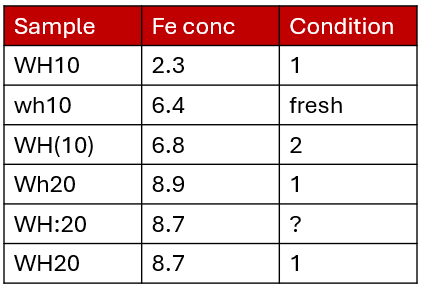
For example, here is a dataset that could benefit from using entry codes. The sample name looks like it would consist of two sample types (WH10 and WH20) but there are multiple ways of writing the sample name. The same thing for condition. You can read our blog post about entry codes which works through the above example. If you have many entry codes you can also import entry codes from other schemas or from a .csv file using the Semantic Engine.
Separate out columns for clarity
Sometimes you may have compressed multiple pieces of information into a single column. For example, your sample identifier might have several pieces of useful information. While this can be very useful for naming samples, you can keep the sample ID and add extra columns where you pull all of the condensed information into separate attributes, one for each ‘fact’. This can help others understand the information coded in your sample names, and also make this information more easily accessible for analysis. Another good example of data that should be separated are latitude and longitude attributes which benefit from being in separate columns.
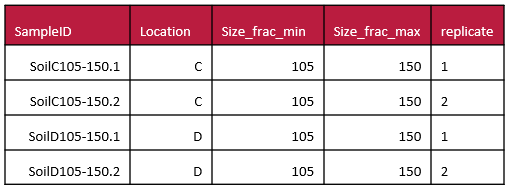
Consider adopting error coding
If your data starts to have codes written in the data as you annotate problems with collection or missing samples, consider putting this information in an adjacent data quality column so that it doesn’t interfere with your data analysis. Your columns of data should contain only one type of information (the data), and annotations about the data can be moved to an adjacent quality column. Read our blog post to learn more about adding quality comments to a dataset using the Semantic Engine.
Look for standards you can use
It can be most helpful if you can find ways to harmonize your work with the community by trying to use standards. For example, there is an ISO standard for date/time values which you could use when formatting these kinds of attributes (even if you need to fight Excel to do so!).
Consider schema reuse
Schemas will often be very specific to a specific dataset, but it can be very beneficial to consider writing your schema to be more general. Think about your own research, do you collect the same kinds of data over and over again? Could you write a single schema that you can reuse for each of these datasets? In research schemas written for reuse are very valuable, such as a complex schema like phenopackets, and reusable schemas help with data interoperability improving FAIRness.
In conclusion, you can do many things to prepare your data for documentation. This will help both you and others understand your data and thinking process better, ensuring greater data FAIRness and higher quality research. You can also contribute back to the community if you develop a schema that others can use and you can publish this schema and give it an identifier such as DOI for others to cite and reuse.
Written by Carly Huitema
How should you organize your files and folders when you start on a research project?
Or perhaps you have already started but can’t really find things.
Did you know that there is a recommendation for that? The TIER protocol will help you organize data and associated analysis scripts as well as metadata documentation. The TIER protocol is written explicitly for performing analysis entirely by scripts but there is a lot of good advice that researchers can apply even if they aren’t using scripts yet.
“Documentation that meets the specifications of the TIER Protocol contains all the data, scripts, and supporting information necessary to enable you, your instructor, or an interested third party to reproduce all the computations necessary to generate the results you present in the report you write about your project.” [TIER protocol]
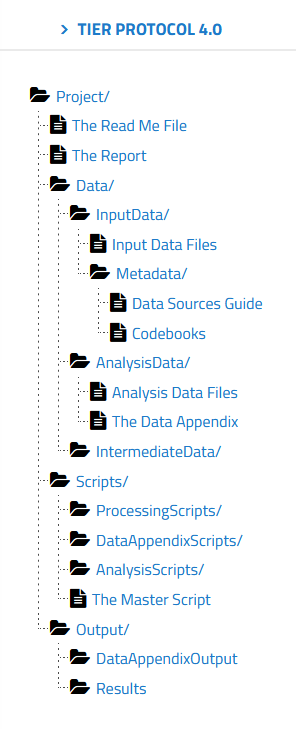
If you go to the TIER protocol website, you can explore the folder structure and read about the contents of each folder. You have folders for raw data, for intermediate data, and data ready for analysis. You also have folders for all the scripts used in your analysis, as well as any associated descriptive metadata.
You can use the Semantic Engine to write the schema metadata, the data that describes the contents of each of your datasets. Your schemas (both the machine-readable format and the human-readable .txt file) would go into metadata folders of the TIER protocol. The TIER protocol calls data schemas “Codebooks”.
Remember how important it is to never change raw data! Store your raw collected data before any changes are made in the Input Data Files folder and never! ever! change the raw data. Make a copy to work from. It is most valuable when you can work with your data using scripts (and stored in the scripts folder of the TIER protocol) rather than making changes to the data directly via (for example) Excel. Benefits include reproducibility and the ease of changing your analysis method. If you write a script you always have a record of how you transformed your data and anyone who can re-run the script if needed. If you make a mistake you don’t have to painstakingly go back through your data and try and remember what you did, you just make the change in the script and re-run it.
The TIER protocol is written explicitly for performing analysis entirely by scripts. If you don’t use scripts to analyze your data or for some of your data preparation steps you should be sure to write out all the steps carefully in an analysis documentation file. If you are doing the analysis for example in Excel you would document each manual step you make to sort, clean, normalize, and subset your data as you develop your analysis. How did you use a pivot table? How did decide which data points where outliers? Why did you choose to exclude values from your analysis? The TIER protocol can be imitated such that all of this information is also stored in the scripts folder of the TIER protocol.
Even if you don’t follow all the directions of the TIER protocol, you can explore the structure to get ideas of how to best manage your own data folders and files. Be sure to also look at advice on how to name your files as well to ensure things are very clear.
Written by Carly Huitema