Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund
Semantic Engine
Semantics is a branch of linguistics and logic concerned with meaning.
The Semantic Engine is a set of tools helping researchers generate machine-accessible meaning for their data.
One of the first tools we are developing will help researchers more easily create and use data schemas. Read our article “Decentralised Semantics: A Semantic Engine User Perspective”
The benefits of better data schemas
Data must be structured to be understood and a schema describes the structure of the data.
To help you understand and use the data you need a well documented data schema. A good schema will tell you what the column labels are and what they mean. It will tell you the units and it will tell you what type of data is in each column.
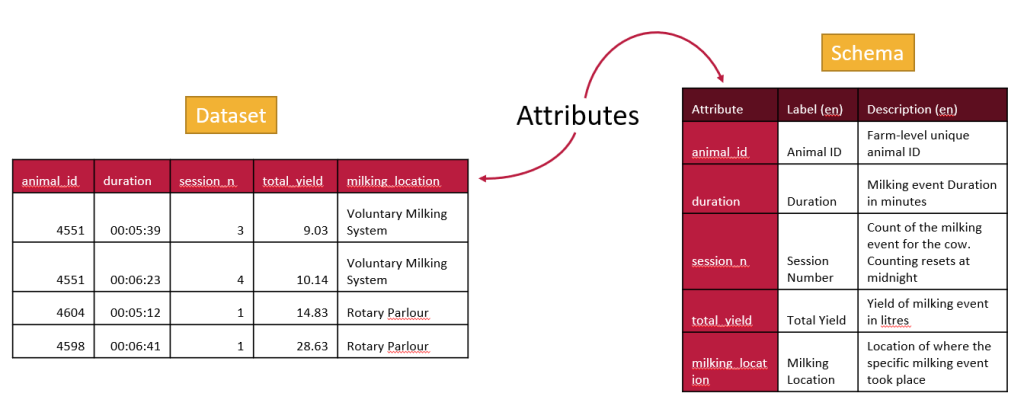
The better a schema is, the more value it adds to the associated data set. Researchers and their collaborators can better document data and avoid misinterpreting data, which can lead to false assumptions in their research.
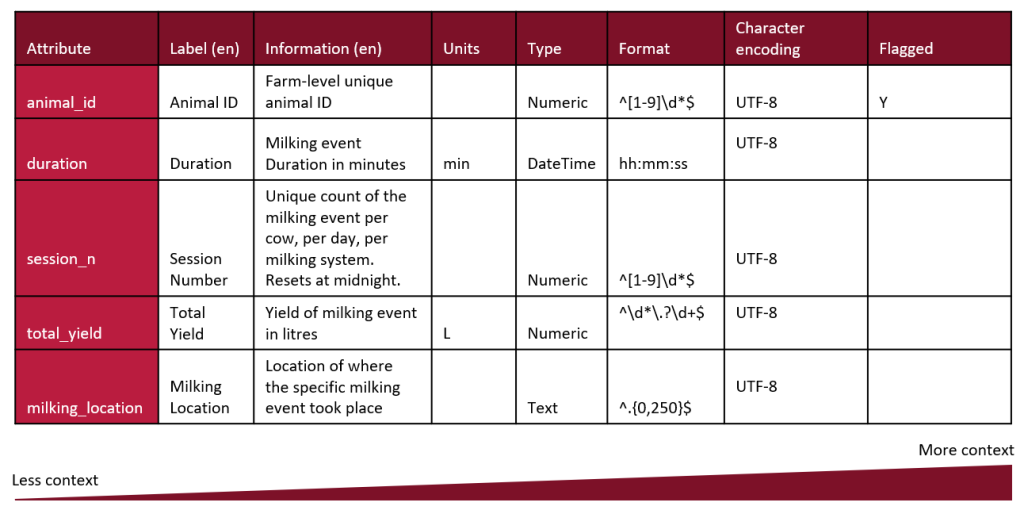
Better data schemas aid researchers in sharing data with the research community. Better documentation enables researchers to effectively communicate the context of the data to other users, ensuring that the information is used accurately. This is especially valuable in cross-disciplinary research where other users are less familiar with the conventions of a particular discipline.
How to easily write better schemas
Effective data schemas can be challenging to write because they require specialized knowledge and time. Agri-food Data Canada is creating a semantic engine to help researchers write better data schemas with less effort. Agri-food Data Canada is developing this semantic engine with the input of researchers to ensure that it meets their needs.
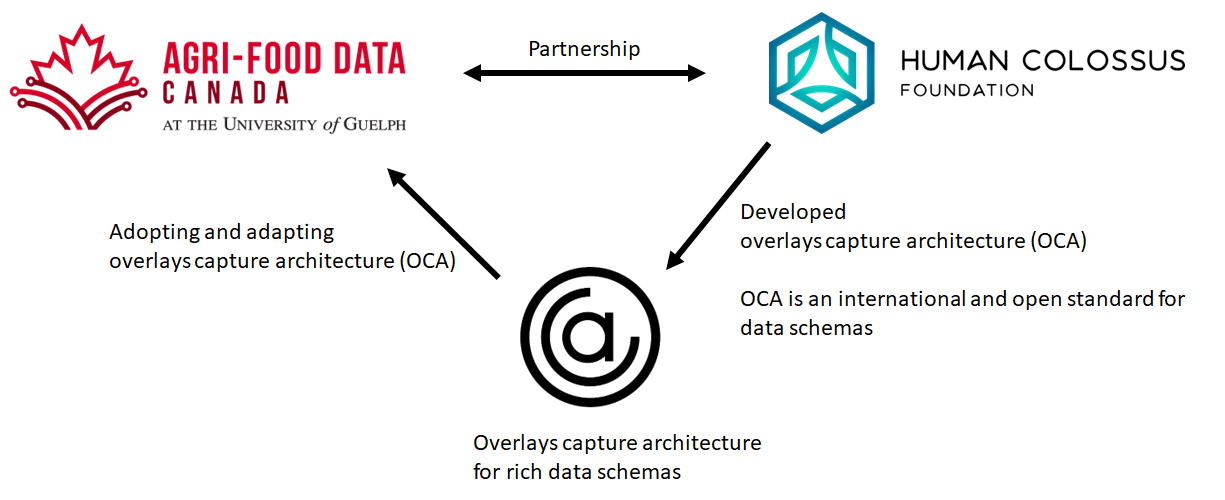
To create the semantic engine, Agri-food Data Canada is partnering with the Human Colossus Foundation to adopt the HCF’s work on overlays capture architecture (OCA) as the underlying schema standard. Overlays capture architecture is an extensible, flexible, international, open, and machine-accessible standard for schemas.
From a table representation of a schema, an OCA schema splits each feature into a separate layer. Each layer is a separate file (written in a machine-readable format) that recognizes the capture base, or the foundation of the schema describing the data set. Layers are added to the schema to provide more detail, making it easier to understand and use data collected and structured according to the associated schema.
The different features of the data schema can be expressed as layers (or overlays) of the capture base. This is the overlays capture architecture, which can be expressed in a machine-readable format.
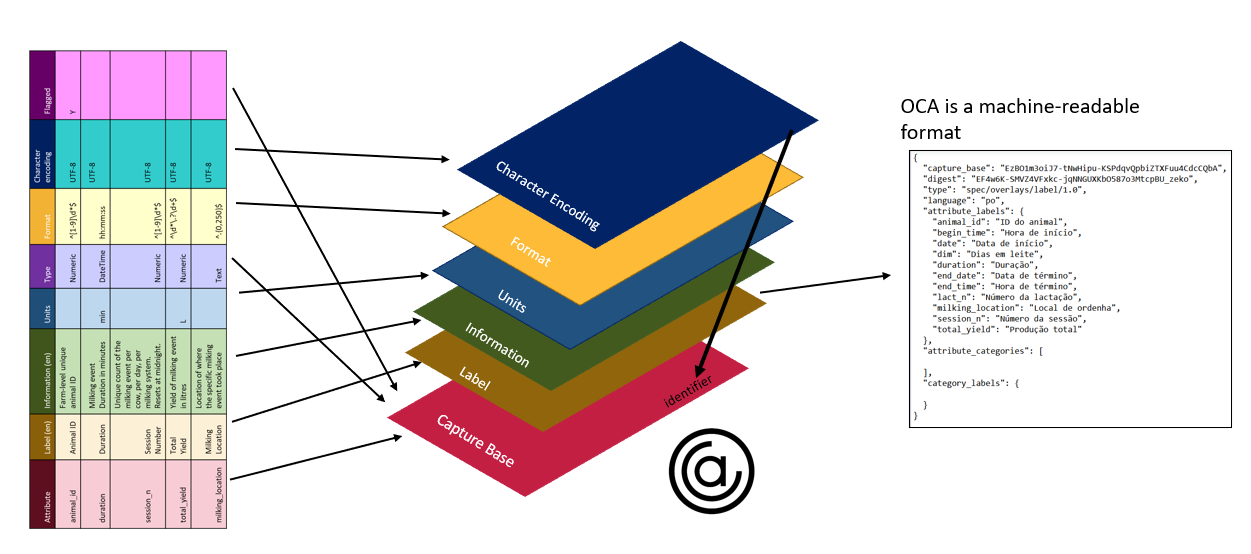
The many benefits of the OCA-layered schema architecture include the following:
- Improved interoperability and extensibility
- Each layer is independent and references the unique identifier of the capture base
- Users can begin with a basic schema, and as it becomes necessary (or popular), they can add layers referencing the capture base and increase schema usability
- Users can extend and improve other people’s schemas to fit their needs. Rather than creating a new schema, users can add new layers while keeping the same capture base, so the data remains interoperable
Layers can be more than just descriptions and labels. For example, a user can add a data transformation layer that contains instructions for transforming data from another schema into their format. This would help users wanting to work with data presented in an unusual format. The data transformation layer records how to transform data from one schema type to another, making data collected with two different capture bases interoperable.
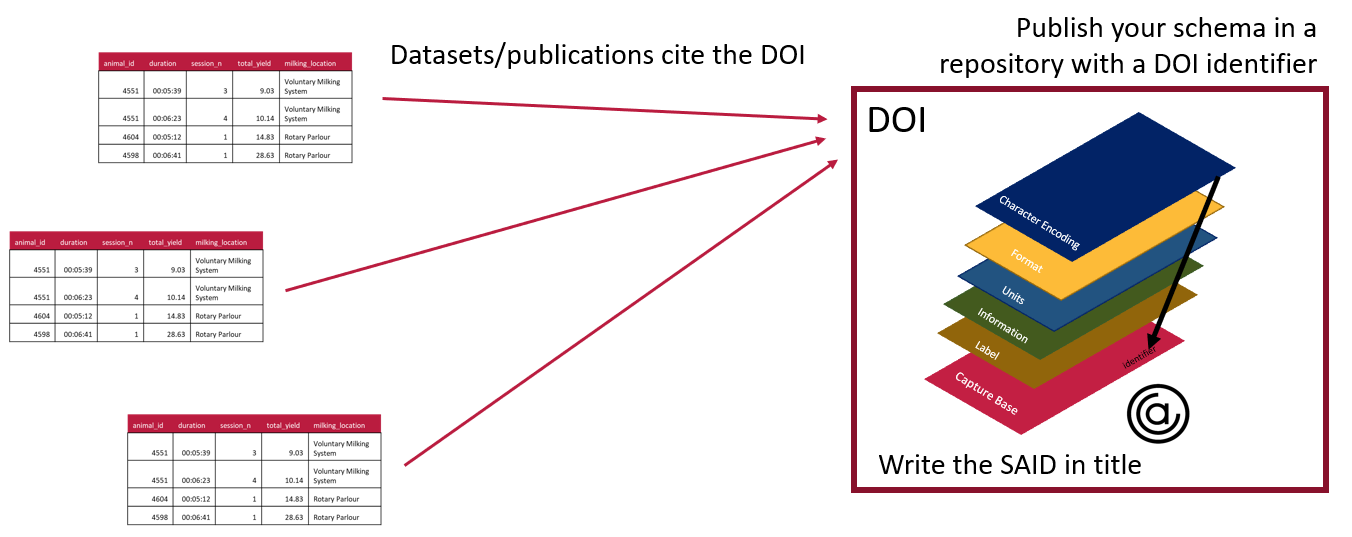
After schemas have been created they can be published as a separate research object. This makes it easier for others to adopt and adapt existing schemas rather than recreating the work. The result is data that is more interoperable and easy to be understood by users.
The semantic engine that Agri-food Data Canada is creating in partnership with the Human Colossus Foundation lets researchers create, use and export schemas using the flexible and extensible OCA standard. The semantic engine will help researchers generate meaningful data.
You can access the Semantic Engine online, download templates, and create your own machine-actionable data schemas.