Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund
Overlays Capture Architecture
A Self-Addressing Identifier (SAIDs) is a key feature of an Overlays Capture Architecture (OCA) schema. SAIDs are a type of digest which are calculated from one-way hashing functions. Let’s break this idea down further and explore.
Hashing functions create digests
A hashing function is a calculation you can perform on something digital. The function takes the input characters, and calculates a fixed-size string of characters which represents the input data. This output, known as a hash value or digest, is unique to the specific input. Even a small change in the input will produce a drastically different hash, a property known as the avalanche effect. A digest becomes the fixed length digital fingerprint of your input.
Another important feature of hashing functions is that they are one-way. You can start with a digital object and calculate a digest, but you cannot go backwards. You cannot take a digest and calculate what the original digital object was.
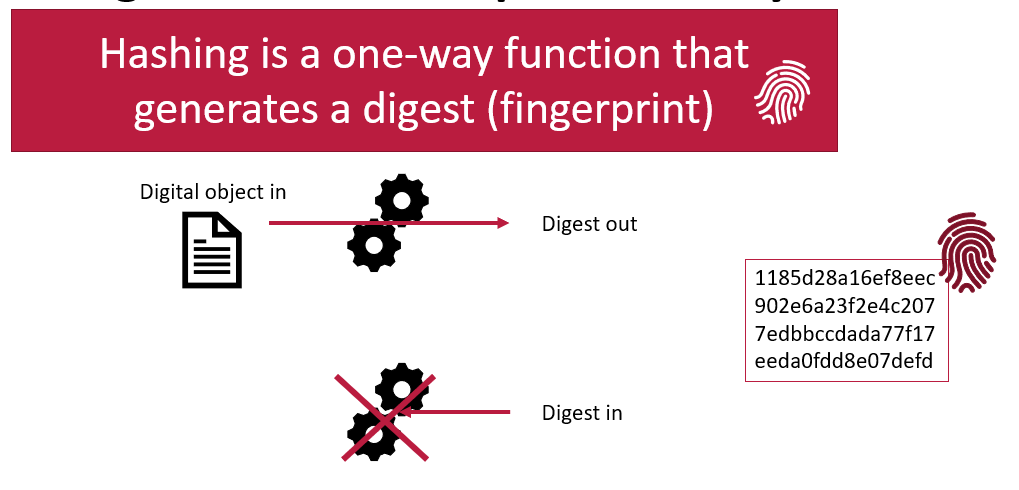
Hashing functions are reproducible
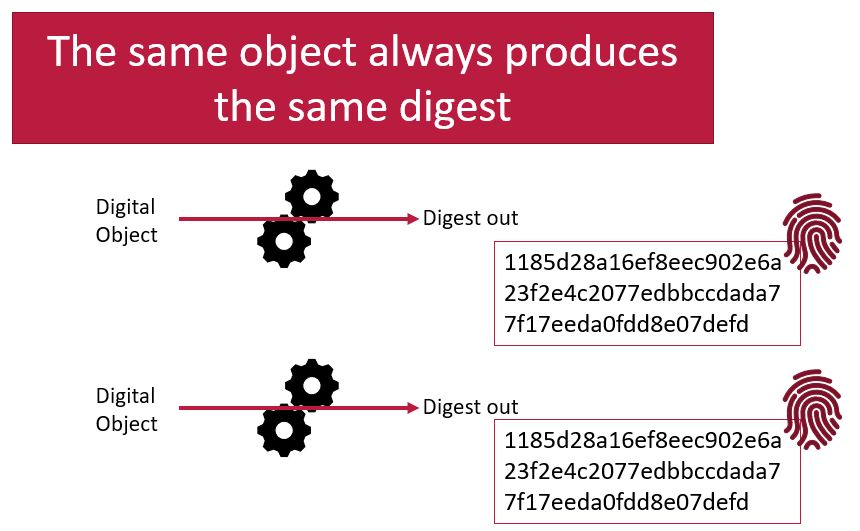
A hashing function will always produce the same digest from the same digital input. This means digests are very reproducible. If you are told what digest to expect when given an digital object, and then you calculate the digest yourself and compare them you can be certain that if the digests are the same, then you have received the original object as expected. If the digests are different, then you know there is a problem somewhere. The digital object you have received is not the one you expected to get. Very slight differences in the digital object (such as adding a single character) will result in drastically different digests.

SAIDs are digests with additional steps
A self-addressing identifier (SAID) is a digest that is embedded into the object it is a hash of. It is now a digest that self-references.
But wait a minute you say! As soon as you add the digest, then the object changes, and therefore the digest changes. This is true. That is why a SAID is digest with a few more steps. When a computer program calculates a SAID it puts a bunch of #’s in the digital object where the SAID is supposed to appear. Then the digest is calculated and that digest replaces the #’s. When you want to verify the SAID, you take out the digest, replace it with #’s, calculate the digest and compare it to the original digest.
A SAID is a digest and it is inserted into a document following reproducible steps. Those who are really into the details can read this in-depth blog posting about the nuances of SAID calculations (and it goes really into the details which can be important to know for implementers!). Users don’t need to know this level of detail but it is important to know it exists.
Using SAIDs
The use of content-addressable identifiers, such as SAIDs, plays a crucial role in ensuring reproducibility. In research workflows, it can be difficult to confirm that a cited digital object is identical to the one originally used. This challenge increases over time as verifying the authenticity of the original object becomes more difficult. By referencing digital objects like schemas with SAIDs, researchers can confidently reproduce workflows using the authentic, original objects. When the SAID in the workflow matches the calculated SAID of the retrieved object, the workflow is verified, enhancing research reproducibility and promoting FAIR research practices.
Conclusion
Content-addressable identifiers like SAIDs are key to ensuring reproducibility in research. By using SAIDs, researchers can confidently reproduce workflows with authentic artifacts, enhancing reproducibility and supporting FAIR practices.
Written by Carly Huitema
With the introduction of using OCA schemas for data verification let’s dig a bit more into the format overlay which is an important piece for data verification.
When you are writing a data schema using the Semantic Engine you can build up your schema documentation by adding features. One of the features that you can add is called format.
In an OCA (Overlays Capture Architeccture) schema, you can specify the format for different types of data. This format dictates the structure and type of data expected for each field, ensuring that the data conforms to certain predefined rules. For example, for a numeric data type, you can define the format to expect only integers or decimal numbers, which ensures that the data is valid for calculations or further processing. Similarly, for a text data type, you can set a format that restricts the input to a specific number of characters, such as a string up to 50 characters in length, or constrain it to only allow alphanumeric characters. By defining these formats, the OCA schema provides a mechanism for validating the data, ensuring it meets the expected requirements.
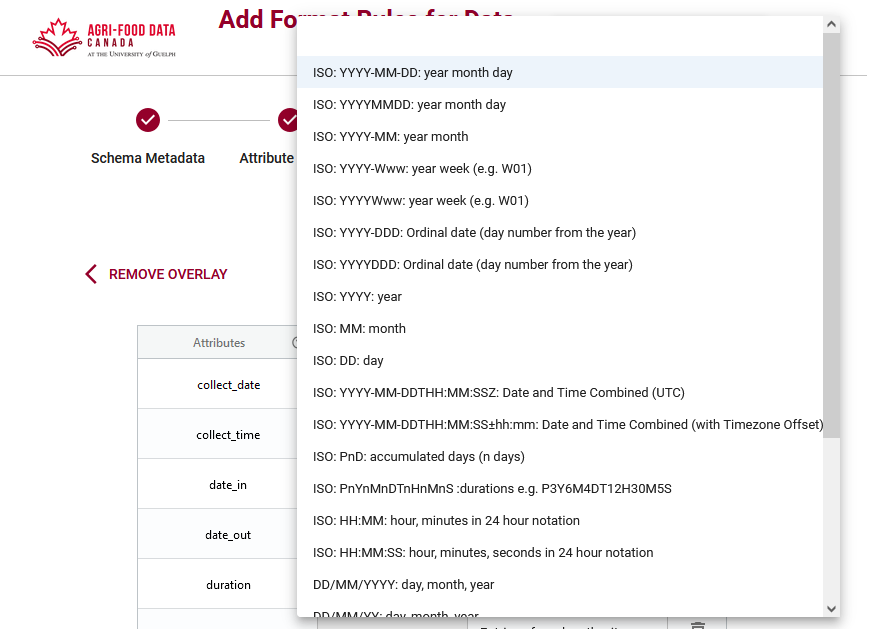
Specifying the format for data in an OCA schema is valuable because it guarantees consistency and accuracy in data entry and validation. By imposing these rules, you can prevent errors such as inputting the wrong type of data (e.g., letters instead of numbers) or exceeding field limits. This level of control reduces data corruption, minimizes the risk of system errors, and improves the quality of the information being collected or shared. When systems across different platforms adhere to these defined formats, it enables seamless data exchange and interoperability improving data FAIRness.
The rules for defining data formats in an OCA schema are typically written using Regular Expressions (RegEx). RegEx is a sequence of characters that forms a search pattern, used for matching strings against specific patterns. It allows for very precise and flexible definitions of what is considered valid data. For example, RegEx can specify that a field should contain only digits, letters, or specific formats like dates (YYYY-MM-DD) or email addresses. RegEx is widely used for input validation because of its ability to handle complex patterns and enforce strict rules on data format, making it ideal for ensuring data consistency in systems like OCA.
To help our users be consistent, the Semantic Engine limits users to a set of format rules, which is documented in the format rule GitHub repository. If the rule you want isn’t listed here it can be added by reaching out to us at ADC or raising a GitHub issue in the repository.
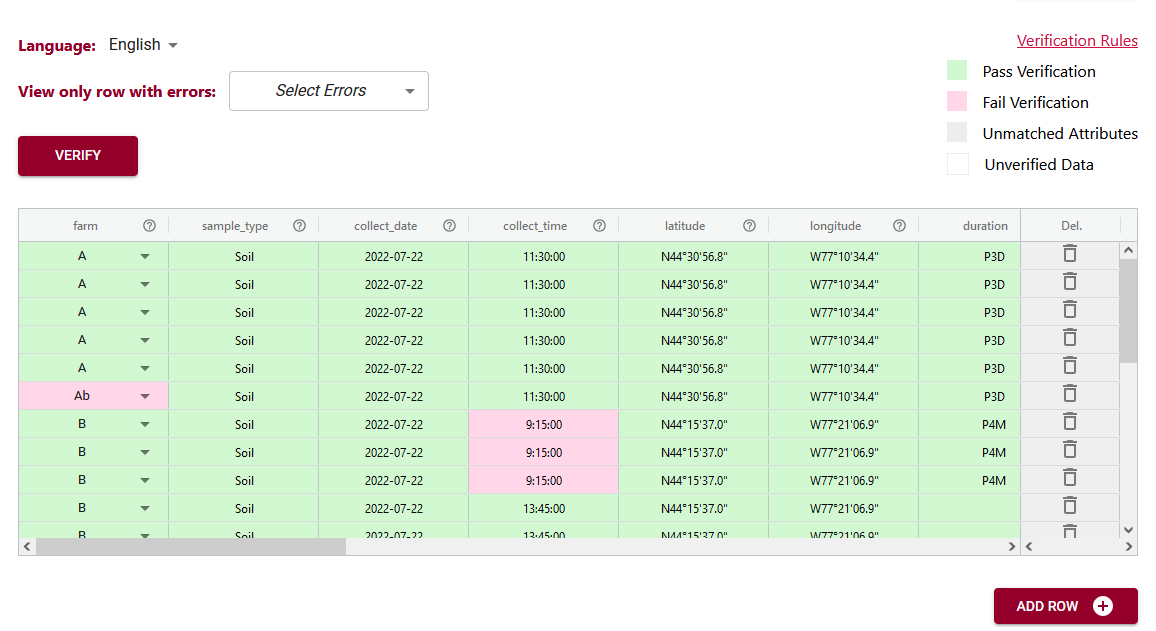
After you have added format rules to your data schema you can use the data verification tool to check your data against your new schema rules.
Written by Carly Huitema
What do you do when you’ve collected data but you need to also include notes in the data. Do you mix the data together with the notes?
Here we build on our previous blog post describing data quality comments with worked examples.
An example of quality comments embedded into numeric data is if you include values such as NULL or NA when you have a data table. Below are some examples of datatypes being assigned to different attributes (variables v1-v8). You can see in v5 that there is are numeric measurements values mixed together with quality notations such as NULL, NA, or BDL (below detection limit).
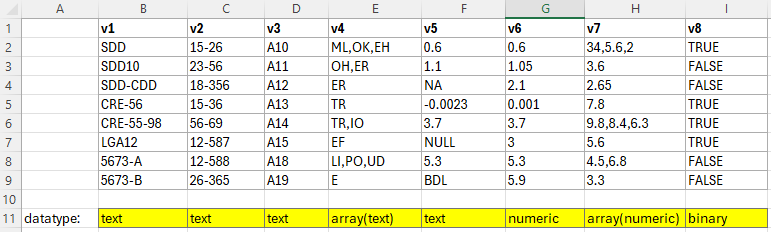
Technically, this type of data would be given the datatype of text when using the Semantic Engine. However, you may wish to use v5 as a numeric datatype so that you can perform analysis with it. You could delete all the text values, but then you would be losing this important data quality information.
As we described in a previous blog post, one solution to this challenge is to add quality comments to your dataset. How you would do this is demonstrated in the next data example.
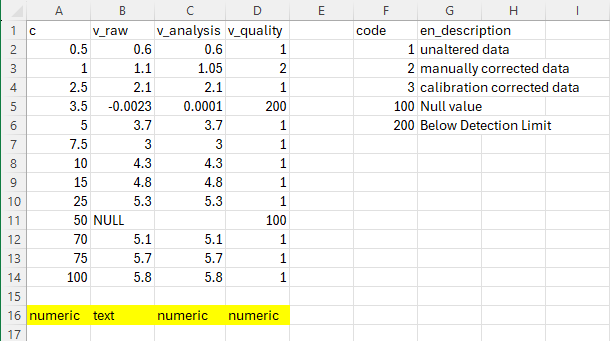
In this next example there are two variables: c and v. Variable v contains a mixture of numeric values and text.
step 1: Rename v to v_raw. It is good practice to always keep raw data in its original state.
step 2: copy the values into v_analysis and here you can remove any text values and make other adjustments to values.
step 3: document your adjustments in a new column called v_quality and using a quality code table.
The quality code table is noted on the right of the data. When using the Semantic Engine you would put this in a separate .csv file and import it as an entry code list. You would also remove the highlighted dataypes (numeric, text etc.) which don’t belong in the dataset but are written here to make it easier to understand.
You can watch the entire example being worked through using the Semantic Engine in this YouTube video. Note that even without using the Semantic Engine you can annotate data with quality comments, the Semantic Engine just makes the process easier.
Written by Carly Huitema
When you create a schema using the Semantic Engine you are documenting information that can make your dataset more FAIR, helping others use and understand your data. The schema created using the Semantic Engine is understood by machines and is written in JSON. At first glance, it is not so easy for people to read JSON which is where the readme.txt file version comes to help. All information of the schema bundle is copied into the readme.txt along with some extra helping information. To support long-term archiving it is important to document using low requirement data formats which is why the plain-text format has been selected for a human-readable, archive ready version of your schema written using the Semantic Engine.
The readme text file begins with reference material. This reference material is the same for every OCA schema readme.txt. At the top it gives the version number of the readme (1.0 in this example), provides citations of where the information is coming from, and gives a short introduction to what a schema is.
BEGIN_REFERENCE_MATERIAL ****************************************************************** OCA_READ_ME/1.0 This is a human-readable schema, based on the OCA schema standard. Reference for Overlays Capture Architecture (OCA): https://doi.org/10.5281/zenodo.7707467 Reference for OCA_READ_ME/1.0: https://github.com/agrifooddatacanada/OCA_README A schema describes details about a dataset. In OCA, a schema consists of a capture_base which documents the attributes and their most basic features. A schema may also contain overlays which add details to the capture_base. For each overlay and capture_base, a hash of their original contents has been calculated and is reported here as the SAID value. This README format documents the capture_base and overlays that were associated together in a single OCA Bundle. OCA_MANIFEST lists all components of the OCA Bundle. For the OCA_BUNDLE, each section between rows of ****'s contains the details of one "layer type/version" of the OCA Bundle. ****************************************************************** END_REFERENCE_MATERIAL
After the reference material we list the manifest – the contents of schema listed overlay by overlay along with their digest identifiers. The digest identifiers are calculated from the contents of the schema components and are written here to help with reproducibility.
BEGIN_OCA_MANIFEST ********************************************************************** Bundle SAID/digest: unavailable capture_base SAID/digest: ElQVB8ffr4TdvPvCgxmHjZxhUR_JcPkuLRpuHY1oU7HA, character_encoding SAID/digest: EKwa4p3qiRjizl-bhiVy-sC5jd8FzNLyhL842vbEGpXM, conformance SAID/digest: ECj97Q3zZQYLyuyHli2x7rLvLaPKmpKkurPnnPMD9wbY, entry (en) SAID/digest: EIbRDpClXxWw202M3D5sTYPq5G4ZnLEta8FvK9lclunQ, entry_code SAID/digest: E6AuDvomYlHQ6k9HMRUCRYQnkESaGPZzh17CkVgsltPo, format SAID/digest: EDozfjgDRT3YzWoGo23E2VYt-Nh4iepYMc3kf02Uh1u4, information (en) SAID/digest: EU-VGxKVUPBqBPqdQvi_pdLBduJvFIjrQJZHKHlBsAvM, label (en) SAID/digest: EgOwKdgjdcEP5y0l8Nx8RmpU74GKB-opBZj7LF-Y1hFc, meta (en) SAID/digest: EUmhlW5XLF7GtyZeToaaP0XNcaOKD61s_48bFCX6J-sw, unit SAID/digest: "EaN1jMNQamXdPTRm-CB4Si5Oj6kt3xjmE2BjXkOzT664" ********************************************************************** END_OCA_MANIFEST
Next comes the components of the schema bundle where each component is separated by a row of *’s. Each layer is described with a name and version (e.g. capture_base layer version 1.0) and the SAID reproduced from the manifest.
In this section, the capture_base is documented with the the schema classification (RDF402) and any attributes marked as sensitive (animal_id). After that comes a list of all the attributes (variables) in the schema along with the attribute’s datatype.
BEGIN_OCA_BUNDLE ********************************************************************** Layer name: capture_base/1.0 SAID/digest: ElQVB8ffr4TdvPvCgxmHjZxhUR_JcPkuLRpuHY1oU7HA classification: RDF402 flagged_attributes: [animal_id] Schema attribute: data type animal_id: Numeric begin_time: DateTime date: DateTime dim: Numeric duration: DateTime end_date: DateTime end_time: DateTime lact_n: Numeric milking_location: Text session_n: Numeric total_yield: Numeric
Each overlay of the schema bundle is documented in the readme.txt file. For example here is the format overlay (version 1.0) listed each attribute and the format feature for each attribute (written in Regular Expressions).
********************************************************************** Layer name: format/1.0 SAID/digest: EDozfjgDRT3YzWoGo23E2VYt-Nh4iepYMc3kf02Uh1u4 Schema attribute: format/1.0 animal_id: ^-?[0-9]+$ begin_time: ^([01][0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]$/gm date: ^(?:(?:19|20)\\d2)-(?:0[1-9]|1[0-2])-(?:0[1-9]|[1-2]\\d|3[0-1])$ dim: ^-?[0-9]+$ duration: ^([01][0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]$/gm end_date: ^(?:(?:19|20)\\d2)-(?:0[1-9]|1[0-2])-(?:0[1-9]|[1-2]\\d|3[0-1])$ end_time: ^([01][0-9]|2[0-3]):[0-5][0-9]:[0-5][0-9]$/gm lact_n: ^-?[0-9]+$ milking_location: ^.050$ session_n: ^-?[0-9]+$ total_yield: ^[-+]?\\d*\\.?\\d+$
One by one, each overlay is described until the end of the schema bundle. The readme.txt file can be renamed to whatever is suitable for your dataset and can be stored as a human-readable and archival version of your schema to accompany your machine-readable JSON version of a schema.
Written by Carly Huitema
At the Semantic Engine we have created a new video example where we walk through the process of describing a dataset with a schema. We are using a dataset with milking data that has been downloaded from the research dairy barn.
You can watch the video on YouTube or follow along in the schema writing tutorial, and then go to the Semantic Engine and write your own dataset schema.
The video covers several tips and tricks that have been discussed here in our blog including:
Importing Entry Codes from another schema
Using ISO standards for dates and times
Written by Carly Huitema
In Overlays Capture Architecture (OCA), when using the Semantic Engine you must assign data types to all of your attributes (aka variables). When do you use the array datatype?
You use an array data type when a data record for that attribute would hold multiple values of a specific data type, arranged in a list-like structure. Multiple values is the key. If you perform a measurement, and you record that single value in your data set, that attribute datatype is not an array of values; it is a single value.
However, if you collect multiple measurements, arrange them into a list using a separator to separate each value, and store that list of values in your dataset in a single record for a single attribute (e.g. in a single Excel cell where each value is separated by a comma), then you have an array.
Array data type example
Here are two examples. The table on the left does not have an array data type (it is datatype=numeric) whereas the table on the right contains an array data type (specifically array[numeric]) and uses a comma separator.
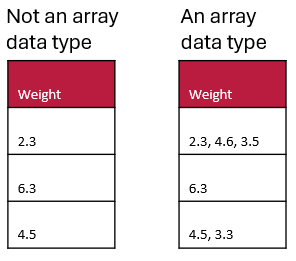
Array data types may be especially useful in questionnaires when you can allow multiple selections for a question (e.g. asking the user to select all the options that apply).
Here are the key characteristics and examples of when you would categorize a data type as an array data type:
- Multiple Elements: An array can store multiple values.
- Same Data Type: All elements in an array must be of the same data type (e.g., all numeric, all strings).
- Indexed Access: Elements in an array can be accessed via their index positions.
In summary, you categorize a data type as an array when it is explicitly defined to contain a collection of elements of the same type, accessible via indices, and useful for storing lists, collections, or sequences of values.
Written by Carly Huitema
Is your data ready to describe using a schema? How can you ensure the fewest hiccups when writing your schema (such as with the Semantic Engine)? What kind of data should you document in your schema and what kinds of data can be left out?
Document data in chunks
When you prepare to describe your data with a schema, try to ensure that you are documenting ‘data chunks’, which can be grouped together based on function. Raw data is a type of data ‘chunk’ that deserves its own schema. If you calculate or manipulate data for presentation in a figure or as a published table you could describe this using a separate schema.
For example, if you take averages of values and put them in a new column and calculate this as a background signal which you then remove from your measurements which you put in another column; this is an summarizing/analyzing process and is probably a different kind of data ‘chunk’. You should document all the data columns before this analysis in your schema and have a separate table (e.g. in a separate Excel sheet) with a separate schema for manipulated data. Examples of data ‘chunks’ include ‘raw data’, ‘analysis data’, ‘summary data’ and ‘figure and table data’. You can also look to the TIER protocol for how to organize chunks of data through your analysis procedures.
Look for Entry Code opportunities
Entry codes can help you streamline your data entry and improve existing data quality.
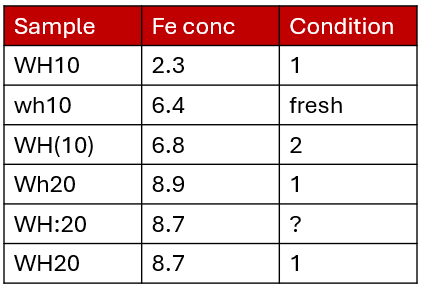
For example, here is a dataset that could benefit from using entry codes. The sample name looks like it would consist of two sample types (WH10 and WH20) but there are multiple ways of writing the sample name. The same thing for condition. You can read our blog post about entry codes which works through the above example. If you have many entry codes you can also import entry codes from other schemas or from a .csv file using the Semantic Engine.
Separate out columns for clarity
Sometimes you may have compressed multiple pieces of information into a single column. For example, your sample identifier might have several pieces of useful information. While this can be very useful for naming samples, you can keep the sample ID and add extra columns where you pull all of the condensed information into separate attributes, one for each ‘fact’. This can help others understand the information coded in your sample names, and also make this information more easily accessible for analysis. Another good example of data that should be separated are latitude and longitude attributes which benefit from being in separate columns.
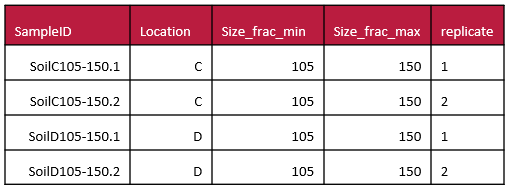
Consider adopting error coding
If your data starts to have codes written in the data as you annotate problems with collection or missing samples, consider putting this information in an adjacent data quality column so that it doesn’t interfere with your data analysis. Your columns of data should contain only one type of information (the data), and annotations about the data can be moved to an adjacent quality column. Read our blog post to learn more about adding quality comments to a dataset using the Semantic Engine.
Look for standards you can use
It can be most helpful if you can find ways to harmonize your work with the community by trying to use standards. For example, there is an ISO standard for date/time values which you could use when formatting these kinds of attributes (even if you need to fight Excel to do so!).
Consider schema reuse
Schemas will often be very specific to a specific dataset, but it can be very beneficial to consider writing your schema to be more general. Think about your own research, do you collect the same kinds of data over and over again? Could you write a single schema that you can reuse for each of these datasets? In research schemas written for reuse are very valuable, such as a complex schema like phenopackets, and reusable schemas help with data interoperability improving FAIRness.
In conclusion, you can do many things to prepare your data for documentation. This will help both you and others understand your data and thinking process better, ensuring greater data FAIRness and higher quality research. You can also contribute back to the community if you develop a schema that others can use and you can publish this schema and give it an identifier such as DOI for others to cite and reuse.
Written by Carly Huitema
Entry codes can be very useful to ensure your data is high quality and to catch mistakes that might mess up with your analysis.
For example, you might have taken multiple measurements of two samples (WH10 and WH20) collected during your research.
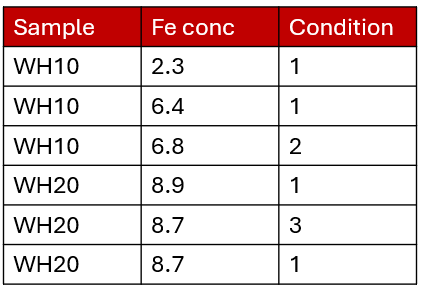
You have a standardized sample name, a measurement (iron concentration) and a condition score for the samples from one to three. You can easily group your analysis into samples because they have consistent names. Incidentally, this is an example of a dataset in a ‘long’ format. Learn more about wide and long formats in our blog post.
The data is clean and ready for analysis, but perhaps in the beginning the data looked more like this, especially if you had multiple people contributing to the data collection:
Sample names and condition scores are inconsistent. You will need to go in and correct the data before you can analyze it (perhaps using a tool such as open refine). Also, if someone else uses your dataset they may not even be aware of the problems, they may not know that the condition score can only have values [1, 2 or 3] and which sample name should be used consistently.
You can help address this problem by documenting this information in a schema using the Semantic Engine with Entry Codes. Look at the figure below to see what entry codes you could use for the data collected.
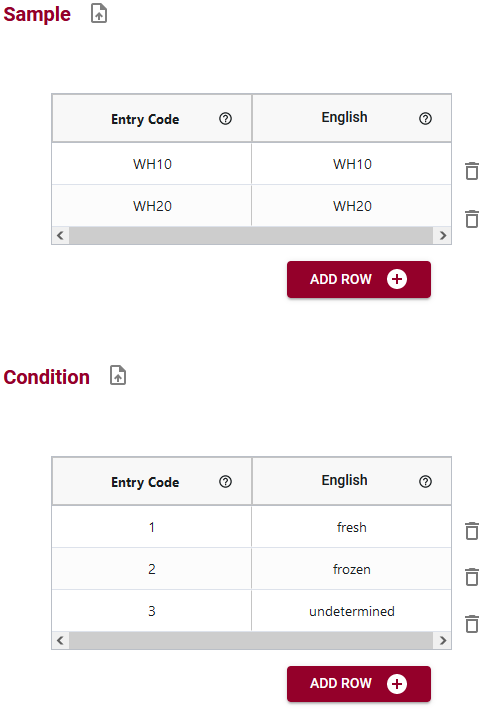
You can see that you have two entry code sets created, one (WH10, WH20) for Sample and one (1, 2, 3) for Condition. It is not always necessary that the labels are different from the entry code itself. Labels become much more important when you are using multiple languages in your schema because it can help with internationalization, or when the label represents some more human understandable concept. In this example we can help understand the Condition codes by providing English labels: 1=fresh sample, 2=frozen sample and 3=unknown condition sample. However, it is very important to note that the entry code (1,2 or 3) and not the label (Fresh, frozen, undetermined) is what appears in the actual dataset.
An example of a complete schema for the above dataset, incorporating entry codes is below:

If you have a long list of entry codes you can even import entry codes in a .csv format or from another schema. For example, you may wish to specify a list of gene names and you can go to a separate database or ontology (or use the unique function in Excel) to extract a list of correct data entry codes.
Entry codes can help you keep your data consistent and accurate, helping to ensure your analysis is correct. You can easily add entry codes when writing your schema using the Semantic Engine.
Written by Carly Huitema
Do we verify that the data is correct? Or do we validate it? These two similar terms have different meanings although the two are often conflated.
For data, we can make the following distinction:
Verification: “Did we collect the data right”
Validation: “Did we collect the right data”
For verification we are asking if the data that we collected is consistent with the rules for the form the data should take. For example, if we insist that all the dates must be in the format YYYY-MM-DD, then we can verify the dataset and check that all the dates are indeed in that format. We might also insist on checking that all p-values are between 0 and 1, or that we are using consistent names for all the farms in the dataset.
With the Semantic Engine, you can write the rules needed to verify the dataset right into the schema using overlays such as the format overlay.

Other rule containing overlays of the schema also contribute verifying a dataset. For example, if a value is required for a specific attribute, then the verification check will make sure there are no blank entries in the dataset for that attribute. If there are entry codes documented in the schema, then data verification will check that only valid entries codes appear in the data for the specific attribute.
Validation is a different beast compared to verification. A researcher collects data to answer a specific research question, such as “Do plants need water to grow”. If you collect data about soil type and plant height and date of death etc. but fail to collect any information about if the plants received water or not, then you are unable to answer the research question. This is of course a trivial example, but it is very easy to get into analysis and realize that you are missing a key variable because you are unable to reach a conclusion. Deciding if your dataset is valid for the research question you are asking is validation and is a key feature of being a researcher.
Typically many people conflate verification and validation, but it becomes very significant especially in a regulatory environment. For example, when the FDA comes and asks for evidence of verification and validation they are asking for very specific things!
The Semantic Engine can help researchers with data verification – did we collect the data right.
Written by Carly Huitema
The Semantic Engine has gotten a recent upgrade for importing entry codes.
If you don’t remember what entry codes are, they help with data standardization and quality by limiting what people can enter in a field for a specific attribute. You can read more about entry codes in our entry code blog post.
Now, the Semantic Engine lets you upload a .csv file that contains your entry codes rather than typing them in individually. You can include the code and multiple languages in your entry code .csv file. Don’t worry if the languages don’t appear in your schema, you will have a chance to pick which ones you want to use.
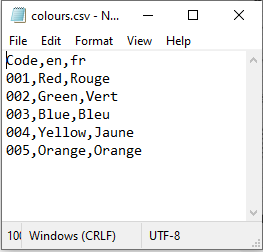
After you have created your .csv file it is time to add them to your schema.
After you have ensured to click ‘list’ for your attribute, it will appear on the screen for adding entry codes. There is an up arrow to select that will let you upload your .csv file containing the entry codes and their labels.
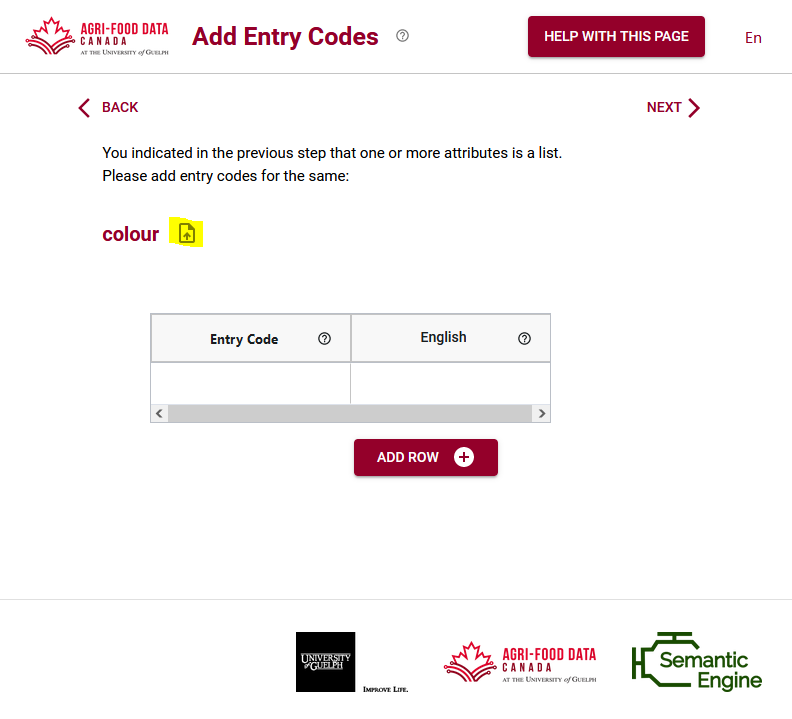
The Semantic Engine will try to auto-match the columns and will give you a screen to check the matching and fill in the correct fields if you need to.
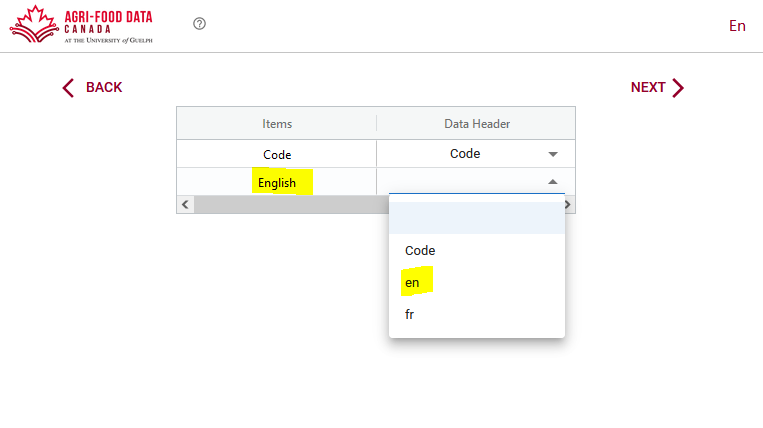
After you have matched columns (and discarded what you don’t need) you now have imported entry codes into your schema. Now you can save the .csv files to reuse when it comes to adding more entry code overlays. It is best practice to include labels for all your languages in your schema, even if they are a repeat of the Code column itself. You can always change it later.
Entry codes are an excellent way to support data quality entry as well as internationalization in your schemas. The Semantic Engine has made it easier to add them using .csv files.
Written by Carly Huitema