Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund
FAIR
I left off my last blog post with a question – well, actually a few questions: WHO owns this data? The supervisor – who is the PI on the research project you’ve been hired onto? OR you as the data collector and analyser? Hmmm…… When you think about these questions – the next question becomes WHO is responsible for the data and what happens to it?
As you already know there really are NO clear answers to these questions. My recommendation is that the supervisor, PI, lab manager, sets out a Standard Operating Procedures (SOP) guide for data collection. Yes, I know this really does NOT address the data ownership question – but it does address my last question: WHO is responsible for the data and what happens to it? And let’s face it – isn’t that just another elephant in the room? Who is responsible for making the research data FAIR?
Oh my, have I just jumped into another rabbit hole?
We have been talking about FAIR data, building tools, and making them accessible to our research community and beyond – BUT? are we missing the bigger vision here? I talk to researchers and most agree that they want to make their data FAIR and share it beyond their lab – BUT…. let’s be honest – that’s a lot of work! Who is going to do it? Here, at ADC, our goal is to work with our research community to help them make agri-food data (and beyond) FAIR – and we’ve been creating tools, creating training materials, and now we are on the precipice of changing the research data culture – well I thought we were – and now I’m left wondering – who is RESPONSIBLE for setting out these procedures in a research project? WHO should be the TRUE force behind changing the data culture and encouraging FAIR research data?
Don’t worry – for anyone reading this – we are VERY set and determined to changing the research data culture by continuing to make the transition to FAIR data – easy and straightforward. It’s just an interesting question and one I would love for you all to consider – WHO is RESPONSIBLE for the data collected in a research project?
Till the next post – let’s consider Copyright and data – oh yes! Let’s tackle that hurdle 🙂
![]()
image created by AI
As data archivists and data analysts, this question crops up a lot! Let’s be honest with ourselves there is NO one answer fits all here! I would love to say YES we should share our data – but then I step back and say HOLD IT! I don’t want anyone being able to access my personal information – so maybe… we shouldn’t share our data. But then the reasonable part of me goes WHOA! What about all that research data? My BSc, MSc, PhD data – that should definitely be shared. But.. should it really? Oh… I can go back and forth all day and provide you with the whys to share data and the why nots to share data. Hmmm…
So, why am I bringing this up now (and again) and in this forum? Conversations I’ve been having with different data creators – that’s it. But why? Because everyone has a different reason why or why not to share their data. So I want us all to take a step back and remember that little acronym FAIR!
I’m finding that more and more of our community recognizes FAIR and what it stands for – but does everyone really remember what the FAIR principles represent? There seems to be this notion that if you have FAIR data it means you are automatically going to share it. I will say NOPE that is not true!!! So if we go back and read the FAIR principles a little closer – you can see that they are referring to the (meta)data!!
Let’s dig into that just a little bit…… Be honest – is there anything secret about the variables you are collecting? Remember we are not talking about the actual data – just the description of what you are collecting. I will argue that about 98% of us are able to share the metadata or description of our datasets. For instance, I am collecting First Name of all respondents, but this is sensitive information. Fabulous!! I now know you are collecting first names and it’s sensitive info, which means it will NOT be shared! That’s great – I know that data will not be shared but I know you have collected it! The data is FAIR! I’ll bet you can work through this for all your variables.
Again – why am I talking about this yet again? Remember our Semantic Engine? What does it do? Helps you create the schema to your dataset! Helps you create or describe your dataset – making it FAIR! We can share our data schemas – we can let others see what we are collecting and really open the doors to potential and future collaborations – with NO data sharing!
So what’s stopping you? Create a data schema – let it get out – and share your metadata!
![]()
image created by AI
Broken links are a common frustration when navigating the web. If you’ve ever clicked on a reference only to land on a “404 Not Found” page, you know how difficult it can be to track down missing content. In research, broken links pose a serious challenge to reproducibility—if critical datasets, software, or methodologies referenced in a study disappear, how can others verify or build upon the original work?
Persistent Identifiers (PIDs) help solve this problem by creating stable, globally unique references to digital and physical objects. Unlike regular URLs, PIDs are designed to persist beyond the lifespan of URL links to a webpage or database, ensuring long-term access to research outputs.
Persistent Identifiers should be used to uniquely (globally) identify a resource, they should persist, and it is very useful if you can resolve them so when you put in the identifier (somewhere) you get taken to the thing it references. Perhaps the most successful PID in research is the DOI – the Digital Object Identifier which is used to provide persistent links to published digital objects such as papers and datasets. Other PIDs include ORCiDs, RORs and many others existing or being proposed.
We can break identifiers into two basic groups – identifiers created by assignment, and identifiers that are derived. Once we have the identifier we have options on how they can be resolved.
Identifiers by assignment
Most research identifiers in use are assigned by the governing body. An identifier is minted (created) for the object they are identifying and is added to a metadata record containing additional information describing the identified object. For example, researchers can be identified with an ORCiD identifier which are randomly generated 16 digit numbers. Metadata associated with the ORCiD value includes the name of the individual it references as well as information such as their affiliations and publications.
We expect that the governance body in charge of any identifier ensures that they are globally unique and that they can maintain these identifiers and associated metadata for years to come. If an adversary (or someone by mistake) altered the metadata of an identifier they could change the meaning of the identifier by changing what resource it references. My DOI associated with my significant research publication could be changed to referencing a picture of a chihuahua.

Other identifiers such as DOIs, PURLs, ARKs and RORs are also generated by assignment and connected to the content they are identifying. The important detail about identifiers by assignment is that if you find something (person, or organism or anything else) you cannot determine which identifier it has been assigned unless you can match it to the metadata of an existing identifier. These assigned identifiers aren’t resilient, they depend on the maintenance of the identifier documentation. If the organization(s) operating these identifiers goes away, so does the identifier. All research that used these identifiers for identifying specific objects has the research equivalent of the web’s broken link.
We also have organizations that create and assign identifiers for physical objects. For example, the American Type Culture Collection (ATCC) mints identifiers, maintains metadata and stores the canonical, physical cell lines and microorganism cultures. If the samples are lost or if ATCC can no longer maintain the metadata of the identifiers then the identifiers lose their connection. Yes, there will be E. coli DH5α cells everywhere around the world, but cell lines drift, and microorganisms growing in labs mutate which was the challenge the ATCC was created to address.
To help record which identifier has been assigned to a digital object you could include the identifier inside the object, and indeed this is done for convenience. Published journal articles will often include the DOI in the footer of the document, but this is not authoritative. Anyway could publish a document and add a fake DOI, it is only the metadata as maintained by the DOI organization that can be considered authentic and authoritative.
Identifiers by derivation
Derived identifiers are those where the content of the identifier is derived from the object itself. In chemistry for example, the IUPAC naming convention provides several naming conventions to systematically identify chemical compounds. While (6E,13E)-18-bromo-12-butyl-11-chloro-4,8-diethyl-5-hydroxy-15-methoxytricosa-6,13-dien-19-yne-3,9-dione does not roll off the tongue, anyone given the chemical structure would derive the same identifier. Digital objects can use an analogous method to calculate identifiers. There exist hashing functions which can reproducibly generate the same identifier (digest) for a given digital input. The md5 checksums sometimes associated with data for download is an example of a digest produced from a hashing function.
An IUPAC name is bi-directional, if you are given the structure you can determine the identifier and vice-versa. A digest is a one-way function – from an identifier you can’t go back and calculate the original content. This one-way feature makes digests useful for identifying sensitive objects such as personal health datasets.
With derived identifiers you have globally unique and secure identifiers which persist indefinitely but this still depends on the authority and authenticity of the method for deriving the identifiers. IUPAC naming rules are authoritative when you can verify the rules to follow come directly from IUPAC (e.g. someone didn’t add their own rules to the set and claim they are IUPAC rules). Hashing functions are also calculated according to a specific function which are typically published widely in the scientific literature, by standards bodies, in public code repositories and in function libraries. An important point about derived identifiers is that you can always verify for yourself by comparing the claimed identifier against the derived value. You can never verify an assigned identifier. The authoritative table maintained by the identifiers governance body is the only source of truth.
The Semantic Engine generates schemas where each component of the schema are given derived identifiers. These identifiers are inserted directly into the content of the schema (as self-addressing identifiers) where they can be verified. The schema is thus a self-addressing document (SAD) which contains the SAID.
Resolving identifiers
Once you have the identifier, how do you go from identifier to object? How do you resolve the identifier? At a basic level, many of these identifiers require some kind of look-up table. In this table will be the identifier and the corresponding link that points to the object the identifier is referencing. There may be additional metadata in this table (like DOI records which also contain catalogue information about the digital object being referenced), but ultimately there is a look-up table where you can go from identifier to the object. Maintaining the look-up table, and maintaining trust in the look-up table is a key function of any governance body maintaining an identifier.
For traditional digital identifiers, the content of the identifier look-up table is either curated and controlled by the governance body (or bodies) of the identifier (e.g. DOI, PURL, ARK), or the content may be contributed by the community or individual (ORCiD, ROR). But in all cases we must depend on the governance body of the identifier to maintain their look-up tables. If something happens and the look-up table is deleted or lost we couldn’t recreate it easily (imagine going through all the journal articles to find the printed DOI to insert back into the look-up table). If an adversary (or someone by mistake) altered the look-up table of an identifier they could change the meaning of the identifier by changing what resource it points to. The only way to correct this or identify it is to depend on the systems the identifier governance body has in place to find mistakes, undo changes and reset the identifier.
Having trust in a governance authority to maintain the integrity of the look-up table is efficient but requires complete trust in the governance authority. It is also brittle in that if the organization cannot maintain the look-up table the identifiers lose resolution. The original idea of blockchain was to address the challenge of trust and resilience in data management. The goal was to maintain data (the look-up table) in a way that all parties could access and verify its contents, with a transparent record of who made changes and when. Instead of relying on a central server controlled by a governance body (which had complete and total responsibility over the content of the look-up table), blockchain distributes copies of the look-up table to all members. It operates under predefined rules for making changes, coupled with mechanisms that make it extremely difficult to retroactively alter the record.
Over time, various blockchain models have emerged, ranging from fully public systems, such as Bitcoin’s energy-intensive Proof of Work approach, to more efficient Proof of Stake systems, as well as private and hybrid public-private blockchains designed for specific use cases. Each variation aims to balance transparency, security, efficiency, and accessibility depending on the application. Many of the Decentralized Identity (the w3c standard DID method) identifiers use blockchains to distribute their look-up tables to ensure resiliency and to have greater trust when many eyes can observe changes to the look-up table (and updates to the look-up table are cryptographically controlled). Currently there are no research identifiers that use any DID method or blockchain to ensure provenance and resiliency of identifiers.
With assigned identifiers only the organization that created the identifier can be the authoritative source of the look-up table. Only the organization holds the authoritative information linking the content to the identifier. For derived identifiers the situation is different. Anyone can create a look-up table to point to the digital resource because anyone can verify the content by recalculating the identifier and comparing it to the expected value. In fact, digital resources can be copied and stored in multiple locations and there can be multiple look-up tables pointing to the same object copied in a number of locations. As long as the identifiers are the same as the calculated value they are all authoritative. This can be especially valuable as organizational funding rises and falls and organizations may lose the ability to maintain look-up tables and metadata directories.
Summary
Persistent identifiers (PIDs) play a crucial role in ensuring the longevity and accessibility of research outputs by providing stable, globally unique references to digital and physical objects. Unlike traditional web links, which can break over time, PIDs persist through governance and resolution mechanisms. There are two primary types of identifiers: those assigned by an authority (e.g., DOIs, ORCiDs, and RORs) and those derived from an object’s content (e.g., IUPAC chemical names and cryptographic hashes). Assigned identifiers depend on a central governance body to maintain their authenticity, whereas derived identifiers allow independent verification by recalculating the identifier. Regardless of their method of generation, both types of identifiers benefit from resolution services which can either be centralized or decentralized. As research infrastructure evolves, balancing governance, resilience, and accessibility in identifier systems remains a key concern for ensuring long-term reproducibility and trust in scientific data.
Written by Carly Huitema
Digests as identifiers
Overlays Capture Architecture (OCA) uses a type of digest called SAIDs (Self-Addressing IDentifiers) as identifiers. Digests are essentially digital fingerprints which provide an unambiguous way to identify a schema. Digests are calculated directly from the schema’s content, meaning any change to the content results in a new digest. This feature is crucial for research reproducibility, as it allows you to locate a digital object and verify its integrity by checking if its content has been altered. Digests ensure trust and consistency, enabling accurate tracking of changes. For a deeper dive into how digests are calculated and their role in OCA, we’ve written a detailed blog post exploring digest use in OCA.
Digests are not limited to schemas, digests can be calculated and used as an identifier for any type of digital research object. While Agri-food Data Canada (ADC) is using digests initially for schemas generated by the Semantic Engine (written in OCA), we envision digests to be used in a variety of contexts, especially for the future identification of research datasets. This recent data challenge illustrates the current problem with tracing data pedigree. If research papers were published with digests of the research data used for the analysis the scholarly record could be better preserved. Even data held in private accounts could be verified that they contain the data as it was originally used in the research study.
Decentralized research
The research ecosystem is in general a decentralized ecosystem. Different participants and organizations come together to form nodes of centralization for collaboration (e.g. multiple journals can be searched by a central index such as PubMed), but in general there is no central authority that controls membership and outputs in a similar way that a government or company might. Read our blog post for a deeper dive into decentralization.
Centralized identifiers such as DOI (Digital Object Identifier) are coordinated by a centrally controlled entity and uniqueness of each identifier depends on the centralized governance authority (the DOI Foundation) ensuring that they do not hand out the same DOI to two different research papers. In contrast, digests such as SAIDs are decentralized identifiers. Digests are a special type of identifier in that no organization handles their assignment. Digests are calculated from the content and thus require no assignment from any authority. Calculated digests are also expected to be globally unique as the chance of calculating the same SAID from two different documents is vanishingly small.
Digests for decentralization
The introduction of SAIDs enhances the level of decentralization within the research community, particularly when datasets undergo multiple transformations as they move through the data ecosystem. For instance, data may be collected by various organizations, merged into a single dataset by another entity, cleaned by an individual, and ultimately analyzed by someone else to answer a specific research question. Tracking the dataset’s journey—where it has been and who has made changes—can be incredibly challenging in such a decentralized process.
By documenting each transformation and calculating a SAID to uniquely identify the dataset before and after each change, we have a tool that helps us gain greater confidence in understanding what data was collected, by whom, and how it was modified. This ensures a transparent record of the dataset’s pedigree.
In addition, using SAIDs allows for the assignment of digital rights to specific dataset instances. For example, a specific dataset (identified and verified with a SAID) could be licensed explicitly for training a particular AI model. As AI continues to expand, tracking the provenance and lineage of research data and other digital assets becomes increasingly critical. Digests serve as precise identifiers within an ecosystem, enabling governance of each dataset component without relying on a centralized authority.
Traditionally, a central authority has been responsible for maintaining records—verifying who accessed data, tracking changes, and ensuring the accuracy of these records for the foreseeable future. However, with digests and digital signatures, data provenance can be established and verified independently of any single authority. This decentralized approach allows provenance information to move seamlessly with the data as it passes between participants in the ecosystem, offering greater flexibility and opportunities for data sharing without being constrained by centralized infrastructure.
Conclusion
Self-Addressing Identifiers such as those used in Overlays Capture Architecture (OCA), provide unambiguous, content-derived identifiers for tracking and governing digital research objects. These identifiers ensure data integrity, reproducibility, and transparency, enabling decentralized management of schemas, datasets, and any other digital research object.
Self-Addressing Identifiers further enhance decentralization by allowing data to move seamlessly across participants while preserving its provenance. This is especially critical as AI and complex research ecosystems demand robust tracking of data lineage and usage rights. By reducing reliance on centralized authorities, digests empower more flexible, FAIR, and scalable models for data sharing and governance.
Written by Carly Huitema
Oh WOW! Back in October I talked about possible places to store and search for data schemas. For a quick reminder check out Searching for Data Schemas and Searching for variables within Data Schemas. I think I also stated somewhere or rather sometime, that as we continue to add to the Semantic Engine tools we want to take advantage of processes and resources that already exist – like Borealis, Lunaris, and odesi. In my opinion, by creating data schemas and storing them in these national platforms, we have successfully made our Ontario Agricultural College research data and Research Centre data FAIR.
But, there’s still a little piece to the puzzle that is missing – and that my dear friends is a catalogue. Oh I think I heard my librarian colleagues sigh :). Searching across National platforms is fabulous! It allows users to “stumble” across data that they may not have known existed and this is what we want. But, remember those days when you searched for a book in the library – found the catalogue number – walked up a few flights of stairs or across the room to find the shelf and then your book? Do you remember what else you did when you found that shelf and book? Maybe looked at the titles of the books that were found on the same shelf as the book you sought out? The titles were not the same, they may have contained different words – but the topic was related to the book you wanted. Today, when you perform a search – the results come back with the “word” you searched for. Great! Fabulous! But it doesn’t provide you with the opportunity to browse other related results. How these results are related will depend on how the catalogue was created.
I want to share with you the beginnings of a catalogue or rather catalogues. Now, let’s be clear, when I say catalogue, I am using the following definition: “a complete list of items, typically one in alphabetical or other systematic order.” (from the Oxford English Dictionary). We have started to create 2 catalogues at ADC – one is the Agri-food research centre schema library listing all the data schemas currently available at the Ontario Dairy Research Centre and the Ontario Beef Research Centre and the second is a listing of data schemas being used in a selection of Food from Thought research projects.
As we continue to develop these catalogues, keep an eye out for more study level information and a more complete list of data schemas.
![]()
image created by AI
Understanding Data Requires Context
Data without context is challenging to interpret and utilize effectively. Consider an example: raw numbers or text without additional information can be ambiguous and meaningless. Without context, data fails to convey its full value or purpose.

By providing additional information, we can place data within a specific context, making it more understandable and actionable – more FAIR. This context is often supplied through metadata, which is essentially “data about data.” A schema, for instance, is a form of metadata that helps define the structure and meaning of the data, making it clearer and more usable.
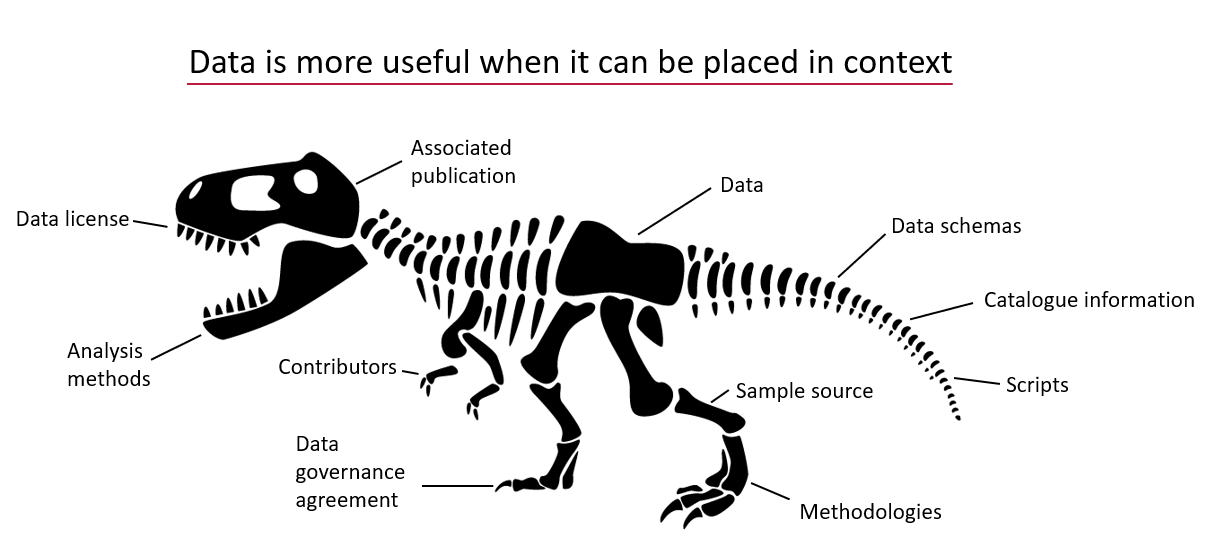
The Role of Schemas in Contextualizing Data
A data schema is a structured form of metadata that provides crucial context to help others understand and work with data. It describes the organization, structure, and attributes of a dataset, allowing data to be more effectively interpreted and utilized.

A well-documented schema serves as a guide to understanding the dataset’s column labels (attributes), their meanings, the data types, and the units of measurement. In essence, a schema outlines the dataset’s structure, making it accessible to users.
For example, each column in a dataset corresponds to an attribute, and a schema specifies the details of that column:
- Units: What units the data is measured in (e.g., meters, seconds).
- Format: What format the data should follow (e.g., date formats).
- Type: Whether the data is numerical, textual, boolean etc.
The more features included in a schema to describe each attribute, the richer the metadata, and the easier it becomes for users to understand and leverage the dataset.

Writing and Using Schemas
When preparing to collect data—or after you’ve already gathered a dataset—you can enhance its usability by creating a schema. Tools like the Semantic Engine can help you write a schema, which can then be downloaded as a separate file. When sharing your dataset, including the schema ensures that others can fully understand and use the data.
Reusing and Extending Schemas
Instead of creating a new schema for every dataset, you can reuse existing schemas to save time and effort. By building upon prior work, you can modify or extend existing schemas—adding attributes or adjusting units to align with your specific dataset requirements.
One Schema for Multiple Datasets
In many cases, one schema can be used to describe a family of related datasets. For instance, if you collect similar data year after year, a single schema can be applied across all those datasets.
Publishing schemas in repositories (e.g., Dataverse) and assigning them unique identifiers (such as DOIs) promotes reusability and consistency. Referencing a shared schema ensures that datasets remain interoperable over time, reducing duplication and enhancing collaboration.
Conclusion
Context is essential to making data understandable and usable. Schemas provide this context by describing the structure and attributes of datasets in a standardized way. By creating, reusing, and extending schemas, we can make data more accessible, interoperable, and valuable for users across various domains.
Written by Carly Huitema
A Self-Addressing Identifier (SAIDs) is a key feature of an Overlays Capture Architecture (OCA) schema. SAIDs are a type of digest which are calculated from one-way hashing functions. Let’s break this idea down further and explore.
Hashing functions create digests
A hashing function is a calculation you can perform on something digital. The function takes the input characters, and calculates a fixed-size string of characters which represents the input data. This output, known as a hash value or digest, is unique to the specific input. Even a small change in the input will produce a drastically different hash, a property known as the avalanche effect. A digest becomes the fixed length digital fingerprint of your input.
Another important feature of hashing functions is that they are one-way. You can start with a digital object and calculate a digest, but you cannot go backwards. You cannot take a digest and calculate what the original digital object was.
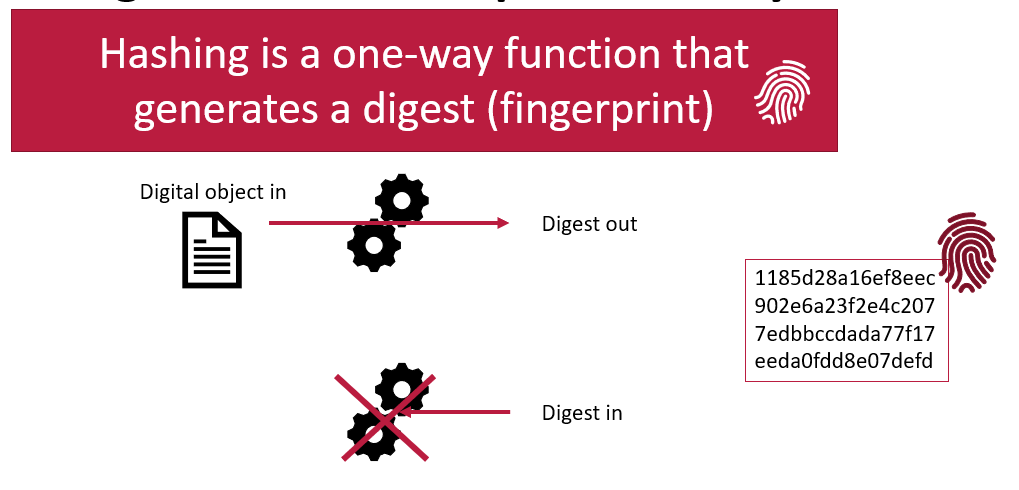
Hashing functions are reproducible
A hashing function will always produce the same digest from the same digital input. This means digests are very reproducible. If you are told what digest to expect when given an digital object, and then you calculate the digest yourself and compare them you can be certain that if the digests are the same, then you have received the original object as expected. If the digests are different, then you know there is a problem somewhere. The digital object you have received is not the one you expected to get. Very slight differences in the digital object (such as adding a single character) will result in drastically different digests.
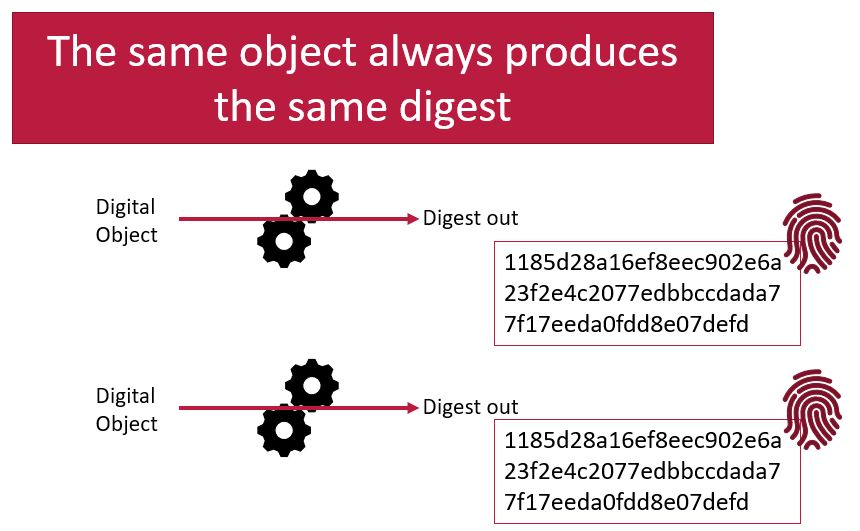

SAIDs are digests with additional steps
A self-addressing identifier (SAID) is a digest that is embedded into the object it is a hash of. It is now a digest that self-references.
But wait a minute you say! As soon as you add the digest, then the object changes, and therefore the digest changes. This is true. That is why a SAID is digest with a few more steps. When a computer program calculates a SAID it puts a bunch of #’s in the digital object where the SAID is supposed to appear. Then the digest is calculated and that digest replaces the #’s. When you want to verify the SAID, you take out the digest, replace it with #’s, calculate the digest and compare it to the original digest.
A SAID is a digest and it is inserted into a document following reproducible steps. Those who are really into the details can read this in-depth blog posting about the nuances of SAID calculations (and it goes really into the details which can be important to know for implementers!). Users don’t need to know this level of detail but it is important to know it exists.
Using SAIDs
The use of content-addressable identifiers, such as SAIDs, plays a crucial role in ensuring reproducibility. In research workflows, it can be difficult to confirm that a cited digital object is identical to the one originally used. This challenge increases over time as verifying the authenticity of the original object becomes more difficult. By referencing digital objects like schemas with SAIDs, researchers can confidently reproduce workflows using the authentic, original objects. When the SAID in the workflow matches the calculated SAID of the retrieved object, the workflow is verified, enhancing research reproducibility and promoting FAIR research practices.
Conclusion
Content-addressable identifiers like SAIDs are key to ensuring reproducibility in research. By using SAIDs, researchers can confidently reproduce workflows with authentic artifacts, enhancing reproducibility and supporting FAIR practices.
Written by Carly Huitema
I have been attending industry-focused meetings over the past month and I’m finding the different perspectives regarding agri-food data very interesting and want to bring some of my thoughts to light.
I first want to talk about my interpretation of the academic views. In research and academia we focus on Research Data Management, how and where does data fit into our research. How can and should we make the data FAIR? During a research project, our focus is on what data to collect, how to collect without bias, how to clean it so we can use it for analysis and eventually draw conclusions to our research question. We KNOW what we are collecting since we DECIDE what we’re collecting. In my statistics and experimental design classes, I would caution my students to only collect what they need to answer their research question. We don’t go off collecting data willy-nilly or just because it looks interesting or fun or because it’s there – there is a purpose.
I’ve also been talking about OAC’s 150th anniversary and how we have been conducting research for many years, yet, the data is no where to be found! Ok, yes I am biased here – as I, personally, want to see all that historical data captured, preserved, and accessible if possible – in other words FAIR. But… what happens when you find those treasure troves of older data and there is little to no documentation? Or the principal investigator has passed on? Do you let the data go? Remember, how I love puzzles and I see these treasure troves as a puzzle – but…. When do you decide that it is not worth the effort? How do you decide what stays and what doesn’t? These are questions that data curators around the world are asking – and ones I’ve been struggling with lately. There is NO easy answer!
In academia, we’ve been working with data and these challenges for decades – now let’s turn our attention to the agri-food industry. Here data has also been collected for decades or more as well – but the data could be viewed more as “personal” data. What happened on my fields or with my animals. Sharing would happen by word of mouth, maybe a local report, or through extension work. Today, though, the data being collected on farms is enormous and growing by the minute – dare I say. As a researcher, I get excited at all that information being collected, but… on a more practical basis – the best way to describe this was penned by a colleague who works in industry – as “So What!”.
Goes back to my statement that we should only collect data that is relevant to our research question. The amount and type of data being collected by today’s farming technology is great but – what are we doing with it? Are producers using it? Is anyone using it? I don’t want to bring the BIG question of data ownership here – so let’s stay practical for a moment – and think about WHY is all that data being collected? WHAT is being done with that data? WHO is going to use it? Oh the questions keep coming – but you get the idea!
In the one meeting I attended – the So What question really resonated with me. We can collect every aspect of what is happening with our soils and crops – but if we can’t use the data when we need it and how we need it – what’s the point?
Yes, I’ve been rambling a bit here, trying to navigate this world of data! So many reasons to make data FAIR and just as many reasons to question making it FAIR. Just as a researcher creates a research question to guide their research, I think we all need to consider the W5 of collecting data: WHO is collecting it, WHAT is being collected, WHERE is it being collected and stored, WHEN is it being collected – on the fly or scheduled, WHY this is the big one!!
A lot to ponder here….
![]()
Using an ontology in agri-food research provides a structured and standardized way to manage the complex data that is common in this field. Ontologies are an important tool to improve data FAIRness.
Ontologies define relationships between concepts, allowing researchers to organize information about crops, livestock, environmental conditions, agricultural practices, and food systems in a consistent manner. This structured approach ensures that data from different studies, regions, or research teams can be easily integrated and compared, helping with collaboration and knowledge sharing across the agri-food domain.
One key advantage of ontologies in agri-food research is their ability to enable semantic interoperability. By using a shared vocabulary and a defined set of relationships, researchers can ensure that the meaning of data remains consistent across different systems and databases. For example, when studying soil health, an ontology can define related terms such as soil type, nutrient content, and pH level, ensuring that these concepts are understood uniformly across research teams and databases.
Moreover, ontologies allow for enhanced data analysis and discovery. They support advanced querying, reasoning, and the ability to infer new knowledge from existing data. In agri-food research, where data is often generated from diverse sources such as satellite imaging, field sensors, and lab experiments, ontologies provide a framework to draw connections between different datasets, leading to insights into food security, climate resilience, and sustainable agriculture.
Agri-food Data Canada is working to make it easier to incorporate ontologies into research by developing tools to help incorporate ontologies into research data.
One way you can connect ontologies to your research data is through Entry Codes (aka pick lists) of a data schema. By limiting entries for a specific attribute (aka variables or data columns) to a selected list drawn from an ontology you can be sure to use terms and definitions that a community has already established. Using the Data Entry Web tool of the Semantic Engine you can verify that your data uses only allowed terms drawn from the entry code list. This helps maintain data quality and ensures it is ready for analysis.
There are many places to find ontologies as a source for terms, the organization CGIAR has published a resource of common Ontologies for agriculture.
Agri-food Data Canada is continuing to develop ways to more easily incorporate standard terms and ontologies into researcher data, helping improve data FAIRness and contributing to better cross-domain data integration.
Written by Carly Huitema
My last post was all about where to store your data schemas and how to search for them. Now let’s take it to the next step – how do I search for what’s INSIDE a data schema – in other words how do I search for the variables or attributes that someone has described in their data schema? A little caveat here – up to this point, we have been trying to take advantage of National data platforms that are already available – how can we take advantage of these with our services? Notice the words in that last statement “up to this point” – yes that means we have some new options and tools coming VERY soon. But for now – let’s see how we can take advantage of another National data repository odesi.ca.
Findable in the FAIR principles?
How can a data schema help us meet the recommendations of this principle? Well…. technically I showed you one way in my last post – right? Finding the data schema or the metadata about our dataset. But let’s dig a little deeper and try another example using the Ontario Dairy Research Centre (ODRC) data schemas to find the variables that we’re measuring this time.
As I noted in my last post there are more than 30 ODRC data schemas and each has a listing of the variables that are being collected. As a researcher who works in the dairy industry – I’m REALLY curious to see WHAT is being collected at the ODRC – by this I mean – what variables, measures, attributes. But, when I look at the README file for the data schemas in Borealis, I have to read it all and manually look through the variable list OR use some keyboard combination to search within the file. This means I need to search for the data schema first and then search within all the relevant data schemas. This sounds tedious and heck I’ll even admit too much work!

BUT! There is another solution – odesi.ca – another National data repository hosted by Ontario Council of University Libraries (OCUL) that curates over 5,700 datasets, and has recently incorporated the Borealis collection of research data. Let’s see what we can see using this interface.
Let’s work through our example – I want to see what milking variables are being used by the ODRC – in other words, are we collecting “milking” data? Let’s try it together:
- Visit odesi.ca

- To avoid the large number of results from any searches, let’s start by restricting our results to the Borealis entries – Under Collection – Uncheck Select All – Select Borealis Research Data
- In the Find Data box type: milking
- Since we are interested in what variables that collect milking data – change Anywhere to Variable

- Click Search
- I see over 20 results – notice that there are Replication dataset results along with the data schema results. The Replication dataset entries refer to studies that have been conducted and whose data has been uploaded and available to researchers – this is fabulous – it shows you how previous projects have also collected milking data.

For our purposes – let’s review the information related to the ODRC Data Schema entries. Let’s pick the first one on my list ODRC data schema: Tie stalls and maternity milkings. Notice that it states there is one Matching Variable? It is the variable called milking_device. If you select the the data schema you will see all the relevant and limited study level metadata along with a DOI for this schema. By selecting the variable you will also see a little more detail regarding the chosen attribute.
NOTE – there is NO data with our data schemas – we have added dummy data to allow odesi.ca to search at a variable level, but we are NOT making any data available here – we are using this interface to increase the visibility of the types of variables we are working with. To access any data associated with these data schemas, researchers need to visit the ODRC website as noted in the associated study metadata.
I hope you found this as exciting as I do! Researchers across Canada can now see what variables and information is being collected at our Research Centres – so cool!!
Look forward to some more exciting posts on how to search within and across data schemas created by the Semantic Engine. Go try it out for yourself!!!
![]()