Preparing data for a schema
Is your data ready to describe using a schema? How can you ensure the fewest hiccups when writing your schema (such as with the Semantic Engine)? What kind of data should you document in your schema and what kinds of data can be left out?
Document data in chunks
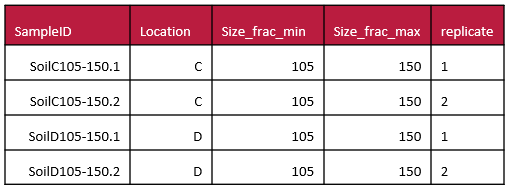
When you prepare to describe your data with a schema, try to ensure that you are documenting ‘data chunks’, which can be grouped together based on function. Raw data is a type of data ‘chunk’ that deserves its own schema. If you calculate or manipulate data for presentation in a figure or as a published table you could describe this using a separate schema.
For example, if you take averages of values and put them in a new column and calculate this as a background signal which you then remove from your measurements which you put in another column; this is an summarizing/analyzing process and is probably a different kind of data ‘chunk’. You should document all the data columns before this analysis in your schema and have a separate table (e.g. in a separate Excel sheet) with a separate schema for manipulated data. Examples of data ‘chunks’ include ‘raw data’, ‘analysis data’, ‘summary data’ and ‘figure and table data’. You can also look to the TIER protocol for how to organize chunks of data through your analysis procedures.
Look for Entry Code opportunities
Entry codes can help you streamline your data entry and improve existing data quality.
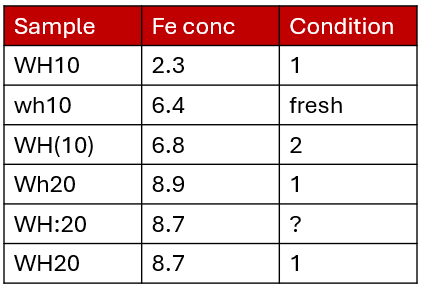
For example, here is a dataset that could benefit from using entry codes. The sample name looks like it would consist of two sample types (WH10 and WH20) but there are multiple ways of writing the sample name. The same thing for condition. You can read our blog post about entry codes which works through the above example. If you have many entry codes you can also import entry codes from other schemas or from a .csv file using the Semantic Engine.
Separate out columns for clarity
Sometimes you may have compressed multiple pieces of information into a single column. For example, your sample identifier might have several pieces of useful information. While this can be very useful for naming samples, you can keep the sample ID and add extra columns where you pull all of the condensed information into separate attributes, one for each ‘fact’. This can help others understand the information coded in your sample names, and also make this information more easily accessible for analysis. Another good example of data that should be separated are latitude and longitude attributes which benefit from being in separate columns.
Consider adopting error coding
If your data starts to have codes written in the data as you annotate problems with collection or missing samples, consider putting this information in an adjacent data quality column so that it doesn’t interfere with your data analysis. Your columns of data should contain only one type of information (the data), and annotations about the data can be moved to an adjacent quality column. Read our blog post to learn more about adding quality comments to a dataset using the Semantic Engine.
Look for standards you can use
It can be most helpful if you can find ways to harmonize your work with the community by trying to use standards. For example, there is an ISO standard for date/time values which you could use when formatting these kinds of attributes (even if you need to fight Excel to do so!).
Consider schema reuse
Schemas will often be very specific to a specific dataset, but it can be very beneficial to consider writing your schema to be more general. Think about your own research, do you collect the same kinds of data over and over again? Could you write a single schema that you can reuse for each of these datasets? In research schemas written for reuse are very valuable, such as a complex schema like phenopackets, and reusable schemas help with data interoperability improving FAIRness.
In conclusion, you can do many things to prepare your data for documentation. This will help both you and others understand your data and thinking process better, ensuring greater data FAIRness and higher quality research. You can also contribute back to the community if you develop a schema that others can use and you can publish this schema and give it an identifier such as DOI for others to cite and reuse.
Written by Carly Huitema