Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund

The Value of Historical Ag Data
Uh-oh here she goes again! I’ve been pondering the direction I wanted to take with this post – do I dig more into the data opportunities that may exist in the OAC Annual reports? or twist my Rubik’s cube to look at a different facet of this ongoing conversation. Let’s look at another facet. You…
View
The Case for Uploadable Form Data
The Case for Uploadable Form Data: A More Flexible Approach to Online Submissions Anyone who has worked extensively with online submission systems will recognize a familiar frustration: you have done the hard work of gathering, drafting, and refining your content – often collaboratively, across multiple documents and tools – and now you face the tedious…
View
AI this and AI that – will it ever end?
Wow! Isn’t it amazing how our world can change in an instant? Remember not that long ago when AI was an up and coming “thing” but not yet a mainstream facet of our research lives? Now it seems everything is about AI or has some AI component to it. I’m not saying that it’s a…
View
Global recognition of SAIDs
Content-Derived Identifiers in the Semantic Engine Built into the Semantic Engine is a particular kind of identifier called a SAID (Self-Addressing Identifier). Unlike traditional identifiers that are assigned to a resource, SAIDs are derived directly from the content itself. They are computed—typically using cryptographic hashing—so the identifier is intrinsically bound to the exact bytes of…
View
To preserve or NOT to preserve data?
That is the question to ask – when it comes to historical research data. So – yes I found some of the original research data that was collected by OAC researchers back in 1877 – BUT… do we spend the time and resources into pulling it out of the PDFs and making it accessible to…
View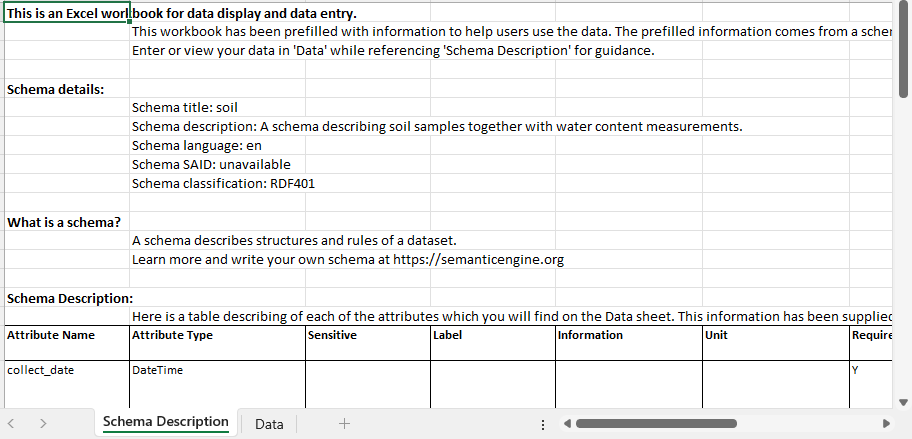
Data Entry Rescue
Imagine this scenario. On her first field season as a principal investigator, a professor watched a graduate student realize—two weeks too late—that no one had recorded soil temperature at the sampling sites. The team had pH, moisture, GPS coordinates… but not the one variable that explained the anomaly in their results. A return trip wasn’t…
View
Historical Research Data Management?
In my last post OAC and Historical Ag Data – has the 150 year old mystery been solved? I ended with a couple of highlighted statements made by the Wm. Johnston, who was the rector/president of OAC back in the early years (1874-1879): conduct experiments and publish the results lay his hands upon our results…
View
OAC and Historical Ag Data – has the 150 year old mystery been solved?
Ah yes I’m on a roll with the historical data. Many of you have heard me ask “Where is the data?” If we have been conducting research or experiments for over 150 years here in Ontario – what do we have to show for it? As Data stewards – what happened? Where has that data…
View
More lost data?
I’m sure by now you’ve heard of the AAFC news – seven research facilities closing with many job cuts. Research facilities with over a century of research, data, reports…. Oh you all know where I’m going with this!!! Yup! Where is all that data? Gone? Hidden? Maybe in some repository? I don’t know! What I…
View
Repositories for Research Data
Generalist and Specialist Data Repositories Research data repositories can be described along two important dimensions: how broad or specialized their scope is, and where they sit in the research data lifecycle. Understanding these distinctions helps understand the technologies and repositories available for research data. Generalist Repositories Generalist repositories are designed to accept many different kinds…
View