Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund
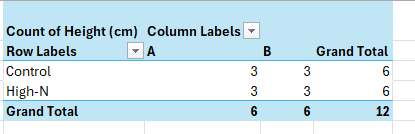
Introduction to Pivot Tables
How Pivot Tables Simplify Analysis of Field Measurements If you’re working with agricultural or experimental data, Excel’s pivot tables can make summarizing results quick and intuitive. Instead of manually calculating averages or totals for each treatment, you can let Excel do the heavy lifting—organizing your measurements by treatment, cultivar, and replicate automatically. The Scenario Suppose…
View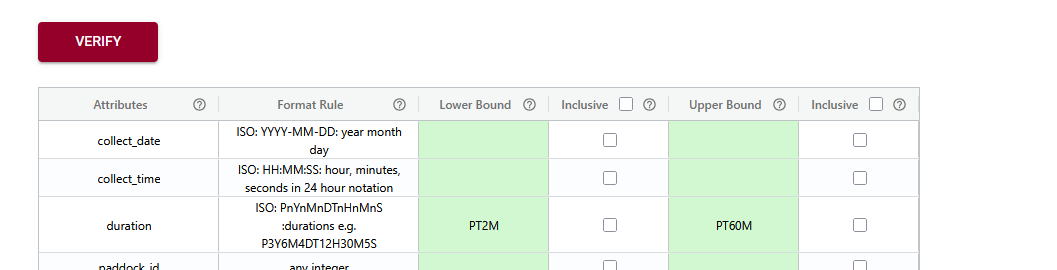
Semantic Engine: Range verification
Streamlining Data Documentation in Research In of research, data documentation is often a complex and time-consuming task. To help researchers better document their data ADC has created the Semantic Engine as a powerful tool for creating structured, machine-readable data schemas. These schemas serve as blueprints that describe the various features and constraints of a dataset,…
View

From Siloed Systems to Shared Success: Building a System That Grows with Your Research
Part of the blog series on Collaborative Research IT Infrastructure In our last post, we explored how shared storage provides more than just space—it delivers reliability, cost-effectiveness, and compliance while ensuring that researchers maintain secure, separate environments. That conversation naturally leads us to the bigger picture: how do we prepare not just for today’s data…
View
AI and data
Alrighty let’s briefly introduce this topic. AI or LLMs are the latest shiny object in the world of research and everyone wants to use it and create really cool things! I, myself, am just starting to drink the Kool-Aid by using CoPilot to clean up some of my writing – not these blog posts –…
View
Derived identifiers in GitHub
At Agri-food Data Canada (ADC), we often emphasize the importance of content-derived identifiers—unique fingerprints generated from the actual content of a resource. These identifiers are especially valuable in research and data analysis, where reproducibility and long-term verification are essential. When you cite a resource using a derived identifier, such as a digest of source code, you’re ensuring…
View
From Siloed Systems to Shared Success: The Benefits of Shared Storage
Part of the blog series on Collaborative Research IT Infrastructure In our last post, we debunked the myth that shared infrastructure reduces research autonomy. In fact, we showed how a shared system can actually enhance flexibility by offering tailored environments, freeing researchers from the burdens of IT management, and fostering seamless collaboration across teams and…
View
RDM in the Real World
Surprise! Surprise! I’m switching gears a bit for this blog post – off my historical data and data ownership pedestal for a bit 🙂 I want to talk about RDM – Research Data Management – today. For the past decade I’ve been working with colleagues offering workshops on this topic and working with the Research…
View
Understanding Metadata at ADC
At Agri-food Data Canada (ADC), we are developing tools to help researchers create high-quality, machine-readable metadata. But what exactly is metadata, and what types does ADC work with? What Is Metadata? Metadata is essentially “data about data.” It provides context and meaning to data, making it easier to understand, interpret, and reuse. While the data…
View
What happened with that “OLD” data anyway?
It’s me again! Yup back to that historical data topic too! I didn’t want to leave everyone wondering what I did with my old data – so I thought I’d take you on a tour of my research data adventures and what has happened to all that data. BSc(Agr) 4th year project data – 1987-1988…
View