Organizing folders for a project
How should you organize your files and folders when you start on a research project?
Or perhaps you have already started but can’t really find things.
Did you know that there is a recommendation for that? The TIER protocol will help you organize data and associated analysis scripts as well as metadata documentation. The TIER protocol is written explicitly for performing analysis entirely by scripts but there is a lot of good advice that researchers can apply even if they aren’t using scripts yet.
“Documentation that meets the specifications of the TIER Protocol contains all the data, scripts, and supporting information necessary to enable you, your instructor, or an interested third party to reproduce all the computations necessary to generate the results you present in the report you write about your project.” [TIER protocol]
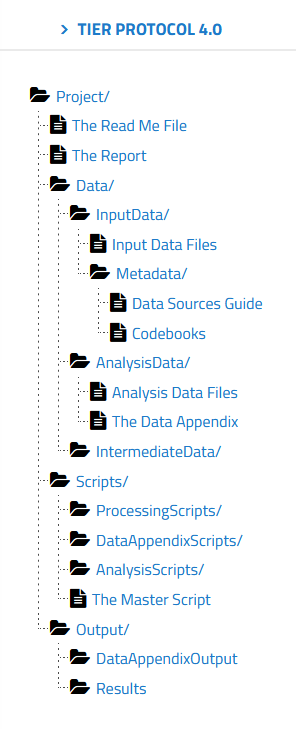
If you go to the TIER protocol website, you can explore the folder structure and read about the contents of each folder. You have folders for raw data, for intermediate data, and data ready for analysis. You also have folders for all the scripts used in your analysis, as well as any associated descriptive metadata.
You can use the Semantic Engine to write the schema metadata, the data that describes the contents of each of your datasets. Your schemas (both the machine-readable format and the human-readable .txt file) would go into metadata folders of the TIER protocol. The TIER protocol calls data schemas “Codebooks”.
Remember how important it is to never change raw data! Store your raw collected data before any changes are made in the Input Data Files folder and never! ever! change the raw data. Make a copy to work from. It is most valuable when you can work with your data using scripts (and stored in the scripts folder of the TIER protocol) rather than making changes to the data directly via (for example) Excel. Benefits include reproducibility and the ease of changing your analysis method. If you write a script you always have a record of how you transformed your data and anyone who can re-run the script if needed. If you make a mistake you don’t have to painstakingly go back through your data and try and remember what you did, you just make the change in the script and re-run it.
The TIER protocol is written explicitly for performing analysis entirely by scripts. If you don’t use scripts to analyze your data or for some of your data preparation steps you should be sure to write out all the steps carefully in an analysis documentation file. If you are doing the analysis for example in Excel you would document each manual step you make to sort, clean, normalize, and subset your data as you develop your analysis. How did you use a pivot table? How did decide which data points where outliers? Why did you choose to exclude values from your analysis? The TIER protocol can be imitated such that all of this information is also stored in the scripts folder of the TIER protocol.
Even if you don’t follow all the directions of the TIER protocol, you can explore the structure to get ideas of how to best manage your own data folders and files. Be sure to also look at advice on how to name your files as well to ensure things are very clear.
Written by Carly Huitema