Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund
Research Infrasctructure
Content-Derived Identifiers in the Semantic Engine
Built into the Semantic Engine is a particular kind of identifier called a SAID (Self-Addressing Identifier). Unlike traditional identifiers that are assigned to a resource, SAIDs are derived directly from the content itself. They are computed—typically using cryptographic hashing—so the identifier is intrinsically bound to the exact bytes of the resource it represents.
These identifiers are not designed to be human-friendly. They are long, opaque strings. But that trade-off enables something more important for research and data systems: verification. If a resource is referenced by a SAID, you can independently confirm that what you have is exactly what was intended. If the content changes, the identifier no longer matches. In that sense, SAIDs are tamper-evident and self-authenticating.
Why Identifier Types Matter in Standards
Many specifications—particularly in research data and interoperability frameworks—depend on identifiers and are explicit about what types are allowed. This ensures consistency, portability, and long-term usability across systems.
One commonly accepted class is the URN (Uniform Resource Name). Because URNs are standardized and designed for persistence, they are frequently permitted in specifications where long-lived, location-independent identifiers are required.
IANA and Global Recognition
The Internet Assigned Numbers Authority (IANA) is responsible for coordinating key elements of the internet’s infrastructure, including identifier namespaces. When IANA registers a namespace, it becomes part of the globally recognized technical foundation used across systems and standards.
SAIDs have now been formally registered with IANA as a new URN namespace: urn:said. This elevates them from an ecosystem-specific mechanism to a globally recognized identifier scheme.
URNs vs URLs
A URN identifies what something is, while a URL (Uniform Resource Locator) identifies where something is located.
URNs are not inherently resolvable—you cannot simply use one to retrieve a resource without additional infrastructure. Instead, they are designed to be persistent names that systems can interpret.
SAIDs fit naturally into this model but add an important property: because they are content-derived, they can be independently verified. Anyone can build a resolver that retrieves content and checks whether it matches the SAID. Trust does not depend on the resolver—it depends on the content itself.
Implications for Research Data Infrastructure
The registration of urn:said means that SAIDs can now be used anywhere URNs are accepted. This has direct implications for research data standards and infrastructure.
The Semantic Engine already uses SAIDs to generate secure, tamper-evident identifiers. With official URN recognition, those identifiers can now integrate cleanly into broader ecosystems—supporting interoperability across repositories, metadata standards, and distributed workflows.
This represents a shift in how identifiers function within research systems. Instead of relying solely on assigned names backed by registries, systems can incorporate identifiers that are self-verifying by design. For research data—where integrity, provenance, and reproducibility are central concerns—this provides a stronger and more flexible foundation.
– Written by Carly Huitema
Generalist and Specialist Data Repositories
Research data repositories can be described along two important dimensions:
-
how broad or specialized their scope is, and
-
where they sit in the research data lifecycle.
Understanding these distinctions helps understand the technologies and repositories available for research data.
Generalist Repositories
Generalist repositories are designed to accept many different kinds of data across disciplines. They prioritize inclusivity and flexibility, offering a common technical platform where researchers can deposit datasets that do not fit neatly into a single domain.
A useful metaphor is the junk drawer in a kitchen. A junk drawer contains many useful items—batteries, spare cables, elastic bands—but finding a specific item often requires some effort. Similarly, generalist repositories can hold valuable datasets, but those datasets may be described with relatively generic metadata and limited domain-specific structure.
As a result, data in generalist repositories can be:
-
Harder to discover through precise searches
-
More difficult to interpret without additional context
-
Less immediately reusable by domain experts
Examples of generalist repositories include Dataverse (Borealis in Canada), Figshare and OSF.
Specialist Repositories
Specialist repositories focus on a specific discipline, data type, or research community. They typically enforce domain-specific metadata standards, controlled vocabularies, and structured submission requirements.
Continuing the kitchen metaphor, specialist repositories resemble a cutlery drawer: clearly organized, purpose-built, and easy to use—provided you are looking for the right type of item. Knives go in one place, forks in another, and everything has a defined role.
Because of this structure, specialist repositories tend to make data:
-
More findable through precise, domain-aware search
-
Easier to interpret due to consistent metadata
-
More interoperable with related tools and systems
-
More reusable for future research
In other words, data in specialist repositories are often more FAIR than data in generalist repositories. However, this specialization also limits what they can accept. Many interdisciplinary datasets—particularly in agri-food research—do not align cleanly with the strict models of existing specialist repositories and therefore end up in generalist ones. Examples of specialist repositories include Genbank, PDB and GEO.
The Research Data Lifecycle: Active and Archival Data
Another important way to think about data repositories is in relation to the research data lifecycle.
Research data typically move through several phases:
-
Planning and collection
-
Processing, active analysis and refinement
-
Publication and dissemination
-
Long-term preservation and reuse
Repositories are often designed to support either active data or archival data, but not both equally well.
Active Data
Active data are produced and used during the course of research. They may be incomplete, frequently updated, or subject to access restrictions due to confidentiality, sensitivity, or competitive concerns.
This is the phase where data are still being cleaned, analyzed, and interpreted. Changes are expected, and collaboration is often ongoing. Most formal repositories are not designed to support this stage, which is typically handled through local storage, shared drives, or project-specific platforms.
Archival Data
Once research is complete and results have been published, data generally move into an archival phase. At this point, datasets are more stable, less likely to change, and often less sensitive—especially if they have been anonymized or if concerns about being “scooped” no longer apply.
Most well-known repositories, including Dataverse, Figshare, and domain-specific archives such as the Protein Data Bank (PDB), are designed primarily for archival data. Their strengths lie in long-term preservation, persistent identifiers (PIDs like DOIs), citation, and access, rather than supporting ongoing analysis or frequent updates.
Bridging the Gaps
It would be inefficient to build a highly specialized repository for every possible type of dataset—much like building a kitchen with a separate drawer for every object that might otherwise end up in the junk drawer. Instead, a more scalable approach is to improve the organization and description of data held in generalist repositories.
Agri-food Data Canada’s approach focuses on developing tools, guidance, and training that help researchers add structure and context to their data wherever it is deposited. By enhancing metadata quality and enabling interoperability between repositories, it becomes possible to make data in generalist repositories more FAIR—without requiring a proliferation of narrowly specialized infrastructure.
Together, specialist and generalist repositories, along with active and archival data systems, form complementary parts of the research data ecosystem. Recognizing their respective roles helps researchers choose appropriate platforms and supports more effective data reuse over time.
Written by Carly Huitema
In Canada, national research data infrastructure is coordinated by the Digital Research Alliance of Canada (DRAC). The Alliance provides the digital tools and platforms that researchers depend on to manage data, perform advanced computing, and leverage research software. Supported by federal funding, DRAC works with partners across the country to expand access, improve security, and strengthen the digital research workforce. These efforts enable Canadian researchers in all disciplines to conduct more efficient, secure, and interoperable research.
As part of the ongoing modernization of Canada’s research infrastructure, DRAC is preparing to introduce a national Registration Agency for Research Activity Identifiers (RAiDs). RAiDs are a relatively new category of persistent identifiers designed to support the accurate identification, management, and linking of research activities—often conceptualized as research “projects”—throughout their full lifecycle.
Why RAiDs Matter
RAiDs provide a globally unique, persistent identifier for a research activity and connect that activity to:
-
People (researchers, collaborators)
-
Organizations (institutions, funders)
-
Outputs (publications, datasets, software)
-
Related resources (grants, ethics approvals, infrastructure)
This enables research projects to be tracked, referenced, and integrated across multiple systems. RAiDs are especially relevant in environments where interoperability is critical, such as national and international research data platforms.
For Canada, RAiDs are being positioned as a foundational component of the Canadian Research Data Platform, where they will facilitate information exchange between services, reduce duplication, and improve project-level transparency across institutions.
How RAiDs Are Minted
A key principle of the RAiD system is that researchers cannot independently mint RAiD identifiers. RAiDs must be generated through a recognized RAiD Service Provider. This approach ensures consistency, quality, and proper registration within the global RAiD infrastructure.
Two other identifiers have other minting processess:
-
ORCID allows individuals to mint their own researcher identifier at the ORCID website.
-
DOIs, however, must be issued by an authorized DOI service provider such as Dataverse, Zenodo, or Figshare.
RAiDs follow the DOI model rather than the ORCID model. Institutions, not individuals, carry the responsibility for minting and maintaining the associated metadata.
As DRAC moves toward becoming a national RAiD Registration Agency, Canadian researchers and institutions will gain a dedicated domestic pathway to obtain RAiDs that are recognized and resolvable globally.
The Global RAiD Registry
All RAiD identifiers and their metadata are maintained in a centralized global registry managed by the International RAiD Data Service, currently coordinated by the Australian Research Data Commons and partner organizations. This registry serves as the authoritative source for RAiD information and provides stable, persistent resolution of RAiD identifiers.
The registry stores:
-
The RAiD itself
-
Descriptive metadata about the research activity
-
Relationships to researchers, institutions, datasets, and grants
-
Activity lifecycle events (start, updates, completion)
-
Version histories and changes over time
Functionally, the RAiD registry operates in a manner similar to:
-
DataCite, which maintains DOI metadata
-
ORCID, which maintains researcher metadata
It is the central location where systems can query, resolve, and verify RAiD information.
The RAiD metadata schema is published openly and can be reviewed at:
https://metadata.raid.org/en/v1.6/index.html
Can Anyone Use the RAiD Metadata Schema?
Any organization—or individual—can choose to document their research activities using the publicly available RAiD metadata model. However, without going through an authorized RAiD Service Provider, they cannot mint an official RAiD identifier, and the resulting record will not be registered in the global RAiD registry or participate in the broader RAiD ecosystem.
Official registration is what ensures global uniqueness, persistent resolution, and interoperability across research platforms.
Conclusion
RAiDs are emerging as a critical component of modern research infrastructure, offering a structured, persistent mechanism for identifying and connecting research activities with all related people, outputs, and systems. The Digital Research Alliance of Canada’s plan to establish a national RAiD Registration Agency represents a significant step toward improving the coordination, traceability, and interoperability of research in Canada.
As Canada’s research ecosystem continues to evolve, the adoption of standardized, globally recognized identifiers like RAiDs will support more transparent, connected, and efficient research workflows—benefiting researchers, institutions, and the broader scientific community.
Written by Carly Huitema
On November 19th, Carly Huitema presented (YouTube link) at the Trust over IP 5-Year Symposium on emerging opportunities to use ORCID as a trust registry to help build secure, verifiable research data spaces. As research becomes increasingly digital and distributed, identity plays a central role in how data is created, shared, and validated. ORCID is already foundational to this ecosystem, and new standards such as Decentralized Identifiers (DIDs) open the door to extending its function beyond its original scope.
ORCID’s Existing Role in Trust and Attribution
For more than a decade, ORCID has provided the research community with a simple but essential service: a persistent, globally unique identifier for every researcher. ORCID IDs sit at the centre of scholarly workflows, connecting people to publications, datasets, affiliations, peer reviews, grants, and contributions.
ORCID IDs reduce ambiguity, streamline reporting, and support better attribution. Because ORCID records are self-maintained, researchers can manage their own scholarly identities while benefiting from integrations with publishers, repositories, and institutions.
One important feature is ORCID’s use of trust signals. When an external organization—such as a university or publisher—adds data to a researcher’s ORCID record, a green check mark appears. This indicates that the information was supplied by a trusted, authenticated source rather than by the researcher alone. These verified entries help create a more authoritative identity record, making ORCID a dependable reference point throughout the research landscape.
Why Bring Decentralized Identifiers Into the Picture?
The W3C’s Decentralized Identifier (DID) standard introduces cryptographically verifiable identifiers designed for secure digital interactions. Unlike traditional identifiers, a DID resolves to a DID Document, which contains:
-
Authentication keys — for proving control of the identifier.
-
Assertion keys — for signing statements such as dataset provenance records.
-
Key agreement keys — for establishing encrypted communication channels.
-
Service endpoints — for interacting with the DID subject or associated services.
The underlying storage of DID data varies depending on the DID method. It may be anchored in distributed ledgers, file systems, websites, or other registries. More than 200 DID methods exist, all interoperable through the same resolution model.
These keys provide practical capabilities:
-
Authenticate into systems using cryptographic proofs.
-
Sign datasets, workflows, and research outputs.
-
Securely transfer data using encrypted channels.
-
Support machine-to-machine operations with verifiable identity.
This aligns closely with the needs of modern research data ecosystems.
Two Proposals: How ORCID Could Support DIDs
Carly’s presentation introduced two possible integration models for combining ORCID with DIDs.
Proposal 1: Researchers List Their DIDs Within ORCID
The simplest model is allowing researchers to store one or more DIDs in their ORCID profile. ORCID remains the authoritative registry for researcher identity, while DIDs provide a layer of cryptographic capability.
This approach would enable:
Provenance Tracking
Researchers could sign datasets, computational workflows, or experimental logs using their DID keys, enabling verifiable provenance across repositories and platforms.
Authentication
DID authentication keys could be used for secure, passwordless login to research infrastructure—HPC clusters, repositories, cloud notebooks, and more.
Secure Data Transfer
Key agreement keys and service endpoints could support encrypted communication channels for sensitive or controlled-access data.
Building Data Spaces on Existing Keys
Research data spaces could use DID information listed in ORCID as a ready-made trust layer, without requiring a separate identity infrastructure.
This model preserves ORCID’s role while extending the capabilities of researcher identifiers.
Proposal 2: ORCID Hosts Full DID Infrastructure
A second, more ambitious additional option is for ORCID to operate DID infrastructure directly. In this model, ORCID could:
-
Allow researchers to create DIDs in addition to listing them.
-
Issue DIDs using DID methods suited for web publication (e.g.,
did:webvh,did:webs). -
Provide self-certifying identifiers with key pre-rotation support.
-
Maintain verifiable histories and cryptographic proofs of key and document changes.
-
Support witnesses or watchers that monitor DID updates.
-
Publish DID Documents via the ORCID registry for portability and persistence.
This would bootstrap more secure research data spaces by giving the entire ecosystem access to standardized, interoperable, verifiable researcher identifiers backed by ORCID’s trust framework.
This technology is freely available as open source tooling either from the Government of British Columbia (DID:webvh) or the KERI Foundation (DID:webs) and could be hosted by any organization (including ADC). The advantage of DIDs are that they are decentralized and can be operated by many different entities, and even used in combination for multi-key security.
Toward a More Verifiable Research Ecosystem
ORCID already plays a central role in identity and attribution. Adding support for Decentralized Identifiers—whether simply listed in profiles or fully hosted by ORCID, ADC or any other research data space – would expand its capabilities to include authentication, digital signatures, secure communication, and cryptographically verifiable provenance.
As research data spaces continue to develop, these capabilities become essential. ORCID’s existing trust signals, combined with DID-based cryptographic assurance, could form a powerful foundation for next-generation research infrastructure—linking people, systems, and data through verifiable, interoperable digital identity.
For further reference about these technologies check out the educational short videos at Bite Size Trust.
Written by Carly Huitema
In research environments, effective data management depends on clarity, transparency, and interoperability. As datasets grow in complexity and scale, institutions must ensure that research data is FAIR; not only accessible but also well-documented, interoperable, and reusable across diverse systems and contexts in research Data Spaces.
The Semantic Engine (which runs OCA Composer), developed by Agri-Food Data Canada (ADC) at the University of Guelph, addresses this need.
What is the OCA Composer
The OCA Composer is based on the Overlays Capture Architecture (OCA), an open standard for describing data in a structured, machine-readable format. Using OCA allows datasets to become self-describing, meaning that each element, unit, and context is clearly defined and portable.
This approach reduces reliance on separate documentation files or institutional knowledge. Instead, OCA schemas ensure that the meaning of data remains attached to the data itself, improving how datasets are shared, reused, and integrated over time. This makes data easier to interpret for both humans and machines.
The OCA Composer provides a visual interface for creating these schemas. Researchers and data managers can build machine-readable documentation without programming skills, making structured data description more accessible to those involved in data governance and research.
Why Use OCA Composer in your Data Space
Implementing standards can be challenging for many Data Spaces and organizations. The OCA Composer simplifies this process by offering a guided workflow for creating structured data documentation. This can help researchers:
- Standardize data descriptions across projects and teams
- Improve dataset discoverability and interoperability
- Support collaboration through consistent documentation templates (e.g. Data Entry Excel)
- Increase transparency and trust in data definitions
By making metadata a central part of data management, researchers can strengthen their overall data strategy.
Integration and Customization
The OCA Composer can support the creation and running of Data Spaces by organizations, departments, research projects and more. These Data Spaces often have unique digital environments and branding requirements. The OCA Composer supports this through embedding and white labelling features. These allow the tool to be integrated directly into existing platforms, enabling users to create and verify schemas while remaining within the infrastructure of the Data Space. Institutions can also apply their own branding to maintain a consistent visual identity.
This flexibility means the Composer can be incorporated into internal portals, research management systems, or open data platforms including Data Spaces while preserving organizational control and customization.
To integrate the OCA Composer in your systems or Data Space, check out our more technical details. Alternatively, consult with Agri-food Data Canada for help, support or as a partner in your grant application.
Written by Ali Asjad and Carly Huitema
At the Ontario Dairy and Beef Research Centres, we’ve reached an exciting milestone: all of our core livestock data — from milk yield and feed intake to activity, body weight, veterinary treatments, health events, and breeding values — is now centralized in a single database. And thanks to our dairy and beef data portals, it’s accessible from one location.
That alone is a major step forward. No more logging into multiple platforms or tracking down reports from different systems. Everything is there — organized, up-to-date, and ready to use.
But while the data is centralized, it’s still separated by source: milk data lives in one table, feed in another, activity in another. We’re pulling this data as raw as we can get it from the original software — which means the next big step is curation and cleaning. Before we can fully unlock the value of this unified database, we need to standardize formats, align timestamps, and prepare the data for cross-system use.
Once that’s in place, we can start to build the next layer: tools to aggregate and connect this data across sources.
I imagine a future where:
- Researchers can download project-specific datasets that combine milk, feed, and health data — no manual merging, no formatting headaches. Just clean, ready-to-analyze files aligned to their study goals.
- Researchers can upload data they collected manually from our animals to this database (e.g., behavioural annotation and blood samples results), so we can have a more comprehansive animal record
- Farm managers can use real-time dashboards that track custom metrics, combining indicators across systems to support daily decisions.
- New research insights — like emerging KPIs or experimental models — can be implemented quickly to support farm management.
This kind of flexibility is only possible because we own the data layer. We haven’t replaced our barn software — we’ve built a foundation underneath it. One that lets us imagine, and soon build, tools that serve both science and farm operations more directly.
Right now, we’re at the edge of that opportunity. The data is in place. The portal is running. The next step is building the features — and doing the behind-the-scenes work — to make this data work harder for everyone who relies on it.
It’s all within reach. The question is: what will we build with it?
Written by Lucas Alcantara
Part of the blog series on Collaborative Research IT Infrastructure
In our last post, we explored why a shared infrastructure makes sense—highlighting how collaborative systems reduce costs, improve security, simplify compliance, and offer scalable, cutting-edge tools for research. But even with all these benefits, one hesitation often remains: the fear of losing control. Many researchers worry that adopting a shared platform means sacrificing flexibility and autonomy. Today, we want to set the record straight.
One of the most persistent myths about shared research infrastructure is that it limits autonomy. For many researchers, the idea of moving to a shared system raises concerns about losing control over their environment, tools, and data. But in reality, a well-designed shared system does the opposite—it empowers researchers by providing the flexibility and support they need to focus on what matters most: their work.
Rather than enforcing a one-size-fits-all approach, shared infrastructure can offer tailored environments that meet the specific needs of individual projects and disciplines. Through tools like virtual machines, containerization, and managed research platforms, researchers gain on-demand access to custom configurations and specialized software—without the burden of setting up and maintaining complex systems themselves. These environments can be as open or restricted as necessary, aligning with project requirements while ensuring data security and compliance.
A shared system also removes the weight of day-to-day IT management. No more worrying about patching servers, configuring backups, or troubleshooting hardware failures. Researchers can reclaim time and energy, redirecting their focus to experiment design, analysis, and discovery. This support is especially critical for smaller teams without dedicated IT personnel, leveling the playing field and enabling broader participation in data-intensive research.
Moreover, shared infrastructure actively facilitates collaboration. Standardized platforms and interoperable systems make it easier to share data, reproduce analyses, and co-author work across departments or even institutions. Whether it’s interdisciplinary teams tackling complex problems or cross-campus initiatives pursuing national funding, a unified infrastructure lowers technical barriers and accelerates collaboration.
Autonomy in research isn’t about managing everything alone—it’s about having the freedom to explore, test, and innovate without unnecessary friction. Shared infrastructure provides that freedom. It brings flexibility, reliability, and scalability together in a way that enhances—not diminishes—researchers’ independence.
Stay tuned for our next post, where we’ll explore the benefits of shared storagee—exploring how scalable, secure, and cost-efficient storage solutions can support everything from active datasets to long-term archives, helping researchers manage data with confidence at every stage.
Written by Lucas Alcantara
Featured picture generated by Pixlr
In previous blog posts, we’ve discussed identifiers—specifically, derived identifiers, which are calculated directly from the digital content they represent. The key advantage of a derived identifier is that anyone can verify that the cited content is exactly what was intended. When you use a derived identifier, it ensures that the digital resource is authentic, no matter where it appears.
In contrast, authoritative identifiers work differently. They must be resolved through a trusted service, and you have to rely on that service to ensure the identifier hasn’t been altered and that the target hasn’t changed.
The Limitations of Derived Identifiers
One drawback of derived identifiers is that they only work for content that can be processed to generate a unique digest. Additionally, once an identifier is created, the content can no longer be updated. This can be a challenge when dealing with dynamic content, such as an evolving dataset or a standard that goes through multiple versions.
This brings us to the concept of identity, which goes beyond a simple identifier.
What Does Identity Mean?
Let’s take an example. The Global Alliance for Genomics and Health (GA4GH) publishes a data standard called Phenopackets. In this case Phenopackets is an identifier. Currently, there are two released versions (and two identifiers). However, anyone could create a new schema and call it “Phenopackets v3.” The key question is: is just naming something and giving it an identifier enough to have it be recognized as Phenopackets v3?
A name is not enough, what also matters is whether GA4GH itself releases “Phenopackets v3.” The identifier alone isn’t enough—we care about who endorses it. In this case, identity comes from GA4GH, the governing organization of Phenopackets.
Identity Through Reputation
Identity is established through reputation which is gained in two main ways:
- Transferred reputation – When an official organization (like GA4GH) endorses an identifier, the identity is backed by its authority and reputation.
- Acquired reputation – Even without a governing body, something gains identity via reputation if it becomes widely recognized and trusted.
For example, Bitcoin was created by an anonymous person (or group) using the pseudonym Satoshi Nakamoto—a name that doesn’t link to any legal identity which could grant it some reputation. Yet, the name Satoshi Nakamoto has strong identity via acquired reputation because of Bitcoin’s success and widespread recognition.
The key is that identity isn’t just about an identifier—it’s about who assigns it and why people trust it. To fully capture identity, we need to track not only the identifier but also the authority or reputation behind it.
How Do We Use an Identity?
Right now, we don’t have a universal system for identifying and verifying identity in a structured, machine-readable way. This is because identity is a combination of both an identifier and associated reputation/authority behind the identity and our current systems for identifiers don’t clearly recognize these two aspects of identity. Instead, we rely on indirect methods, like website URLs and domain names, to be a stand-in for the identity authority.
For example, if you want to verify the Phenopackets schema’s identity you would want to search out its associated authority. You might search for the Phenopackets name (the identifier) online or follow a link to its official GitHub repository. But how do you know that the GitHub page is legitimate? To confirm, you would check if the official GA4GH website links to it. Otherwise, anyone could create a GitHub repository and name it Phenopackets. The identifier is not enough, you also need to find the authority associated with the identity.
Another example of how we present the authority behind an identity are the academic journals. When they publish research, they add their reputation and peer-review process to build the reputation and identity of a paper. However, this system has flaws. When researchers cite papers they use DOIs which are specific identifiers of the journal article. The connection between the publication’s DOI to the identity of the paper is not standardized which makes discovery of important changes to the paper such as corrections and retractions challenging. Sometimes when you find the article on the journal webpage you might also find the retraction notice but this doesn’t always happen. This disconnect between identifiers and identity of publications leads to the proliferation of zombie publications which continue to be used even after they have been debunked.
Future Directions
As it stands, we lack effective tools for managing digital identity. This gap creates risks, including identity impersonation and difficulties in tracking updates, corrections, or retractions. Because our current citation system focuses on identifiers without strong linksing them to identity, important information can get lost. Efforts are underway to address these challenges, but we’re still in the early stages of finding solutions.
One early technology to address the growth of an identity has been Decentralized Identifiers (DIDs). We’ll talk more about them later, but they allow an identifier to be assigned to an identity that evolves and is provably under the control of an associated governance authority.
We hope this post has helped clarify the distinction between identifiers and identity which are often entangled — and why finding better ways to assign and verify identity is a problem worth solving.
Written by Carly Huitema
Broken links are a common frustration when navigating the web. If you’ve ever clicked on a reference only to land on a “404 Not Found” page, you know how difficult it can be to track down missing content. In research, broken links pose a serious challenge to reproducibility—if critical datasets, software, or methodologies referenced in a study disappear, how can others verify or build upon the original work?
Persistent Identifiers (PIDs) help solve this problem by creating stable, globally unique references to digital and physical objects. Unlike regular URLs, PIDs are designed to persist beyond the lifespan of URL links to a webpage or database, ensuring long-term access to research outputs.
Persistent Identifiers should be used to uniquely (globally) identify a resource, they should persist, and it is very useful if you can resolve them so when you put in the identifier (somewhere) you get taken to the thing it references. Perhaps the most successful PID in research is the DOI – the Digital Object Identifier which is used to provide persistent links to published digital objects such as papers and datasets. Other PIDs include ORCiDs, RORs and many others existing or being proposed.
We can break identifiers into two basic groups – identifiers created by assignment, and identifiers that are derived. Once we have the identifier we have options on how they can be resolved.
Identifiers by assignment
Most research identifiers in use are assigned by the governing body. An identifier is minted (created) for the object they are identifying and is added to a metadata record containing additional information describing the identified object. For example, researchers can be identified with an ORCiD identifier which are randomly generated 16 digit numbers. Metadata associated with the ORCiD value includes the name of the individual it references as well as information such as their affiliations and publications.
We expect that the governance body in charge of any identifier ensures that they are globally unique and that they can maintain these identifiers and associated metadata for years to come. If an adversary (or someone by mistake) altered the metadata of an identifier they could change the meaning of the identifier by changing what resource it references. My DOI associated with my significant research publication could be changed to referencing a picture of a chihuahua.

Other identifiers such as DOIs, PURLs, ARKs and RORs are also generated by assignment and connected to the content they are identifying. The important detail about identifiers by assignment is that if you find something (person, or organism or anything else) you cannot determine which identifier it has been assigned unless you can match it to the metadata of an existing identifier. These assigned identifiers aren’t resilient, they depend on the maintenance of the identifier documentation. If the organization(s) operating these identifiers goes away, so does the identifier. All research that used these identifiers for identifying specific objects has the research equivalent of the web’s broken link.
We also have organizations that create and assign identifiers for physical objects. For example, the American Type Culture Collection (ATCC) mints identifiers, maintains metadata and stores the canonical, physical cell lines and microorganism cultures. If the samples are lost or if ATCC can no longer maintain the metadata of the identifiers then the identifiers lose their connection. Yes, there will be E. coli DH5α cells everywhere around the world, but cell lines drift, and microorganisms growing in labs mutate which was the challenge the ATCC was created to address.
To help record which identifier has been assigned to a digital object you could include the identifier inside the object, and indeed this is done for convenience. Published journal articles will often include the DOI in the footer of the document, but this is not authoritative. Anyway could publish a document and add a fake DOI, it is only the metadata as maintained by the DOI organization that can be considered authentic and authoritative.
Identifiers by derivation
Derived identifiers are those where the content of the identifier is derived from the object itself. In chemistry for example, the IUPAC naming convention provides several naming conventions to systematically identify chemical compounds. While (6E,13E)-18-bromo-12-butyl-11-chloro-4,8-diethyl-5-hydroxy-15-methoxytricosa-6,13-dien-19-yne-3,9-dione does not roll off the tongue, anyone given the chemical structure would derive the same identifier. Digital objects can use an analogous method to calculate identifiers. There exist hashing functions which can reproducibly generate the same identifier (digest) for a given digital input. The md5 checksums sometimes associated with data for download is an example of a digest produced from a hashing function.
An IUPAC name is bi-directional, if you are given the structure you can determine the identifier and vice-versa. A digest is a one-way function – from an identifier you can’t go back and calculate the original content. This one-way feature makes digests useful for identifying sensitive objects such as personal health datasets.
With derived identifiers you have globally unique and secure identifiers which persist indefinitely but this still depends on the authority and authenticity of the method for deriving the identifiers. IUPAC naming rules are authoritative when you can verify the rules to follow come directly from IUPAC (e.g. someone didn’t add their own rules to the set and claim they are IUPAC rules). Hashing functions are also calculated according to a specific function which are typically published widely in the scientific literature, by standards bodies, in public code repositories and in function libraries. An important point about derived identifiers is that you can always verify for yourself by comparing the claimed identifier against the derived value. You can never verify an assigned identifier. The authoritative table maintained by the identifiers governance body is the only source of truth.
The Semantic Engine generates schemas where each component of the schema are given derived identifiers. These identifiers are inserted directly into the content of the schema (as self-addressing identifiers) where they can be verified. The schema is thus a self-addressing document (SAD) which contains the SAID.
Resolving identifiers
Once you have the identifier, how do you go from identifier to object? How do you resolve the identifier? At a basic level, many of these identifiers require some kind of look-up table. In this table will be the identifier and the corresponding link that points to the object the identifier is referencing. There may be additional metadata in this table (like DOI records which also contain catalogue information about the digital object being referenced), but ultimately there is a look-up table where you can go from identifier to the object. Maintaining the look-up table, and maintaining trust in the look-up table is a key function of any governance body maintaining an identifier.
For traditional digital identifiers, the content of the identifier look-up table is either curated and controlled by the governance body (or bodies) of the identifier (e.g. DOI, PURL, ARK), or the content may be contributed by the community or individual (ORCiD, ROR). But in all cases we must depend on the governance body of the identifier to maintain their look-up tables. If something happens and the look-up table is deleted or lost we couldn’t recreate it easily (imagine going through all the journal articles to find the printed DOI to insert back into the look-up table). If an adversary (or someone by mistake) altered the look-up table of an identifier they could change the meaning of the identifier by changing what resource it points to. The only way to correct this or identify it is to depend on the systems the identifier governance body has in place to find mistakes, undo changes and reset the identifier.
Having trust in a governance authority to maintain the integrity of the look-up table is efficient but requires complete trust in the governance authority. It is also brittle in that if the organization cannot maintain the look-up table the identifiers lose resolution. The original idea of blockchain was to address the challenge of trust and resilience in data management. The goal was to maintain data (the look-up table) in a way that all parties could access and verify its contents, with a transparent record of who made changes and when. Instead of relying on a central server controlled by a governance body (which had complete and total responsibility over the content of the look-up table), blockchain distributes copies of the look-up table to all members. It operates under predefined rules for making changes, coupled with mechanisms that make it extremely difficult to retroactively alter the record.
Over time, various blockchain models have emerged, ranging from fully public systems, such as Bitcoin’s energy-intensive Proof of Work approach, to more efficient Proof of Stake systems, as well as private and hybrid public-private blockchains designed for specific use cases. Each variation aims to balance transparency, security, efficiency, and accessibility depending on the application. Many of the Decentralized Identity (the w3c standard DID method) identifiers use blockchains to distribute their look-up tables to ensure resiliency and to have greater trust when many eyes can observe changes to the look-up table (and updates to the look-up table are cryptographically controlled). Currently there are no research identifiers that use any DID method or blockchain to ensure provenance and resiliency of identifiers.
With assigned identifiers only the organization that created the identifier can be the authoritative source of the look-up table. Only the organization holds the authoritative information linking the content to the identifier. For derived identifiers the situation is different. Anyone can create a look-up table to point to the digital resource because anyone can verify the content by recalculating the identifier and comparing it to the expected value. In fact, digital resources can be copied and stored in multiple locations and there can be multiple look-up tables pointing to the same object copied in a number of locations. As long as the identifiers are the same as the calculated value they are all authoritative. This can be especially valuable as organizational funding rises and falls and organizations may lose the ability to maintain look-up tables and metadata directories.
Summary
Persistent identifiers (PIDs) play a crucial role in ensuring the longevity and accessibility of research outputs by providing stable, globally unique references to digital and physical objects. Unlike traditional web links, which can break over time, PIDs persist through governance and resolution mechanisms. There are two primary types of identifiers: those assigned by an authority (e.g., DOIs, ORCiDs, and RORs) and those derived from an object’s content (e.g., IUPAC chemical names and cryptographic hashes). Assigned identifiers depend on a central governance body to maintain their authenticity, whereas derived identifiers allow independent verification by recalculating the identifier. Regardless of their method of generation, both types of identifiers benefit from resolution services which can either be centralized or decentralized. As research infrastructure evolves, balancing governance, resilience, and accessibility in identifier systems remains a key concern for ensuring long-term reproducibility and trust in scientific data.
Written by Carly Huitema
What does it mean for research to be decentralized? And how does this relate to ADC? I will use Learning Digital Identity (see also this blog post by the author Phil Windley) for definitions as I think it does the best job.
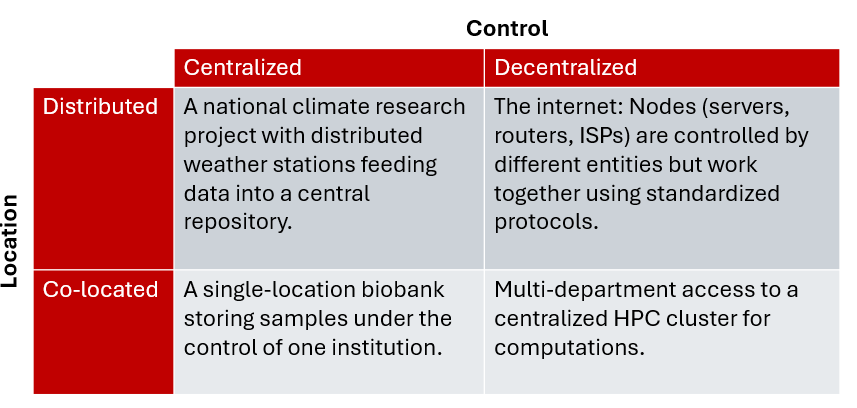
Centralized – Decentralized axis: This axis describes the control of the system. Is the system under the control of a single entity or multiple entities?
Distributed – Co-located axis: This axis describes the location of the system.
Here are some examples:
Co-Located and Centralized
- Examples:
- A standalone server in a data center managed by a single company.
- A single-location biobank storing samples under the control of one institution.
- Characteristics:
- All components are physically or logically co-located.
- Single entity has full control, making coordination simpler.
Co-Located and Decentralized
- Examples:
- A shared core facility in a research institution, such as a microscopy center used by multiple research groups.
- Multi-department access to a centralized HPC cluster for computations.
- Characteristics:
- Components are co-located physically or logically.
- Coordination requires agreements or standards between entities.
Distributed and Centralized
- Examples:
- A research network where one institution operates a centralized database pulling data from distributed studies.
- A cloud platform like AWS or Google Cloud, where distributed servers across the globe are controlled by a single organization.
- A national climate research project with distributed weather stations feeding data into a central repository.
- Characteristics:
- Components are geographically or logically distributed.
- Centralized control simplifies governance but requires robust coordination tools.
Distributed and Decentralized
- Examples:
- The internet: Nodes (servers, routers, ISPs) are controlled by different entities but work together using standardized protocols.
- Blockchain networks like Bitcoin or Ethereum, where no single entity controls all nodes.
- International collaborations like the Large Hadron Collider (LHC), where experiments are distributed across institutions worldwide and no single entity has full control.
- Characteristics:
- Infrastructure and activities are distributed among many entities.
- Coordination is achieved through agreements, protocols, and shared governance, often requiring significant effort to maintain interoperability
Implications
In general, many aspects of research are distributed and decentralized. Health data often has rules about where it can be stored and shared ensuring it will always be co-located. Different researchers work together on projects without a central governance authority that can determine the work of its members. Centralization and co-location of resources can be very useful, with instances of groups coming together to share collective benefits. However, even these nodes of centralization will not join a single platform of all research data run by a single organization. Imagine how successful the World Wide Web would have been if the design had been to build a single server to host all the webpages and a single governance authority to coordinate and approve all the work?
At Agri-food Data Canada we recognize the reality of research, that it needs significant coordination through shared standards and protocols. Indeed, the FAIR principles; that digital objects to be more Findable, Accessible, Interoperable and Reusable (FAIR), supports more efficient and better decentralized and distributed systems. ADC is supporting the development of better standards and protocols and improving decentralized and distributed research by following the FAIR principles and producing tools such as the Semantic Engine. The Semantic Engine helps users write better, machine-readable schemas that can be used across the ecosystem by any participant, helping to maintain data interoperability and contributing to data reuse.
The Semantic Engine also embeds the use of digests into its research data objects. These digests (specifically, Self Addressing IDentifiers or SAIDs) are an important feature of a decentralized and distributed research data ecosystem because no central authority controls the issuance of SAIDs and they can be used throughout the entire research ecosystem while maintaining their meaning. Read more about this in an upcoming blog post!
Written by Carly Huitema