Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund

Let’s talk “Metadata”
You’ve seen this word thrown around a lot! Data about data. Data Documentation. Information about your data. So many different ways to define “metadata”. If you’ve been reading our blog posts – you know that we are STRONG advocates for data documentation!! I, personally, am a STRONG believer in metadata – without it – all…
View
Research Activity Identifiers (RAiDs)
In Canada, national research data infrastructure is coordinated by the Digital Research Alliance of Canada (DRAC). The Alliance provides the digital tools and platforms that researchers depend on to manage data, perform advanced computing, and leverage research software. Supported by federal funding, DRAC works with partners across the country to expand access, improve security, and…
View
How do we change the data culture? Or do we need to?
Happy New Year and welcome back to a whole new year of blog posts by ADC! A New Year is upon us and yet I’m still stuck questioning the value of data and how everyone else values data. I know I talked a bit about this last year in my What happened with the “old”…
View
Happy Holidays!
Happy Holidays from the team at Agri-food Data Canada! See you in 2026 with a series of new blogposts! image created by AI
View
Data Collaboration
I recently had the opportunity to conduct an in-person workshop at the Cultivating Resilience: Building Climate-Smart Food Systems Together Summit in Vancouver, BC. The Summit was hosted by the Agricultural Genomics Action Centre sister hub to the Climate-Smart Data Collaboration Centre, in which ADC is an active partner and supporter. I chose to talk…
View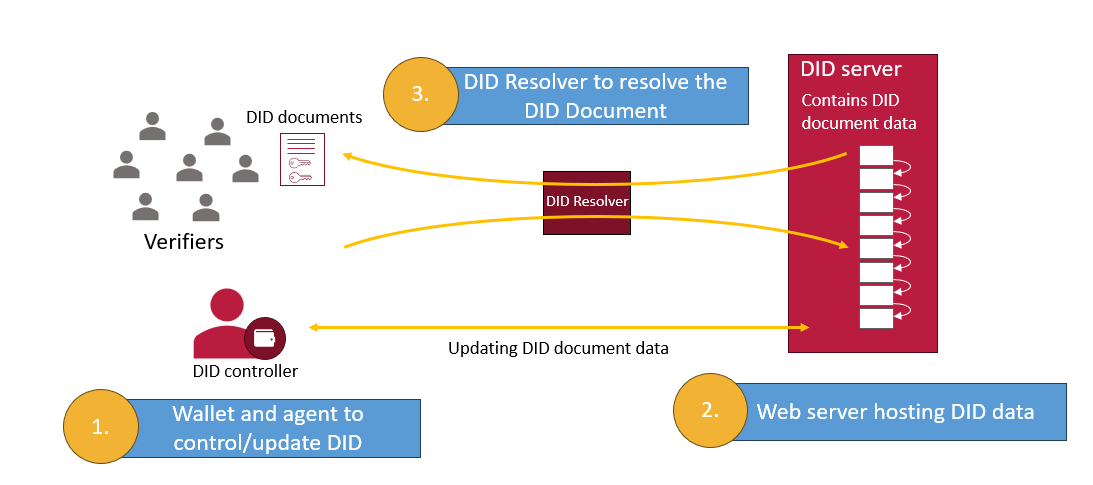
ORCID and Decentralized Identifiers
On November 19th, Carly Huitema presented (YouTube link) at the Trust over IP 5-Year Symposium on emerging opportunities to use ORCID as a trust registry to help build secure, verifiable research data spaces. As research becomes increasingly digital and distributed, identity plays a central role in how data is created, shared, and validated. ORCID is…
View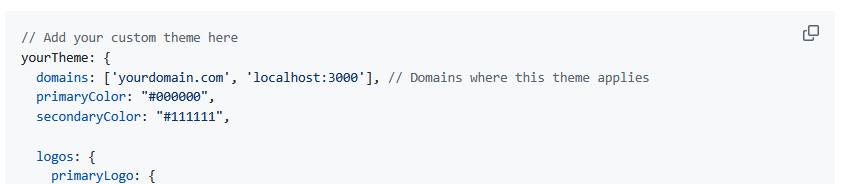
Supporting Data Spaces: OCA Composer
In research environments, effective data management depends on clarity, transparency, and interoperability. As datasets grow in complexity and scale, institutions must ensure that research data is FAIR; not only accessible but also well-documented, interoperable, and reusable across diverse systems and contexts in research Data Spaces. The Semantic Engine (which runs OCA Composer), developed by Agri-Food…
View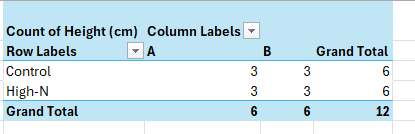
Introduction to Pivot Tables
How Pivot Tables Simplify Analysis of Field Measurements If you’re working with agricultural or experimental data, Excel’s pivot tables can make summarizing results quick and intuitive. Instead of manually calculating averages or totals for each treatment, you can let Excel do the heavy lifting—organizing your measurements by treatment, cultivar, and replicate automatically. The Scenario Suppose…
View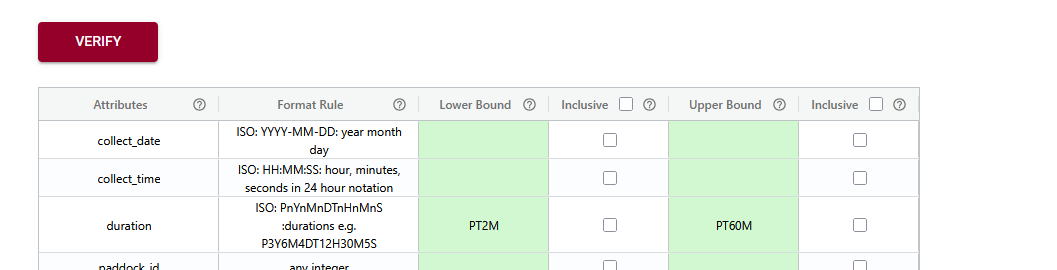
Semantic Engine: Range verification
Streamlining Data Documentation in Research In of research, data documentation is often a complex and time-consuming task. To help researchers better document their data ADC has created the Semantic Engine as a powerful tool for creating structured, machine-readable data schemas. These schemas serve as blueprints that describe the various features and constraints of a dataset,…
View