What is a Self-Addressing Identifier?
A Self-Addressing Identifier (SAIDs) is a key feature of an Overlays Capture Architecture (OCA) schema. SAIDs are a type of digest which are calculated from one-way hashing functions. Let’s break this idea down further and explore.
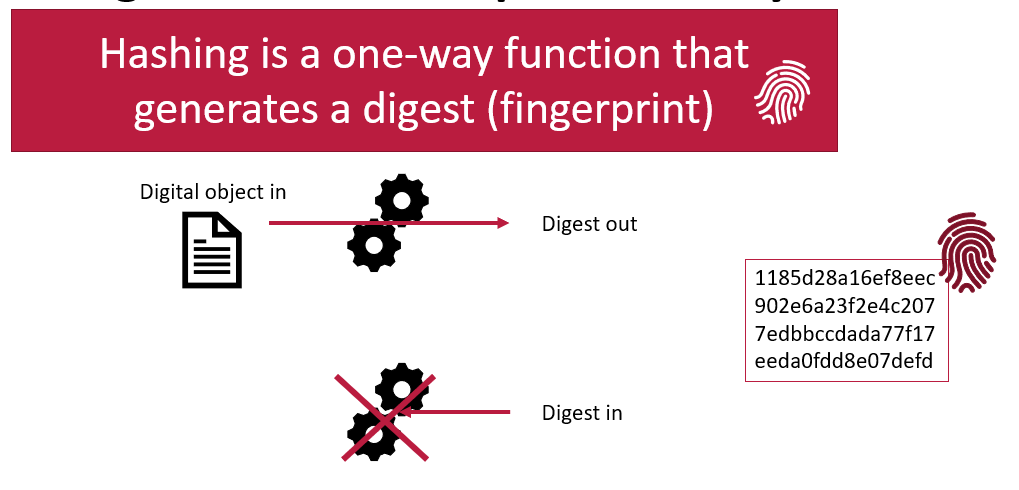
Hashing functions create digests
A hashing function is a calculation you can perform on something digital. The function takes the input characters, and calculates a fixed-size string of characters which represents the input data. This output, known as a hash value or digest, is unique to the specific input. Even a small change in the input will produce a drastically different hash, a property known as the avalanche effect. A digest becomes the fixed length digital fingerprint of your input.
Another important feature of hashing functions is that they are one-way. You can start with a digital object and calculate a digest, but you cannot go backwards. You cannot take a digest and calculate what the original digital object was.
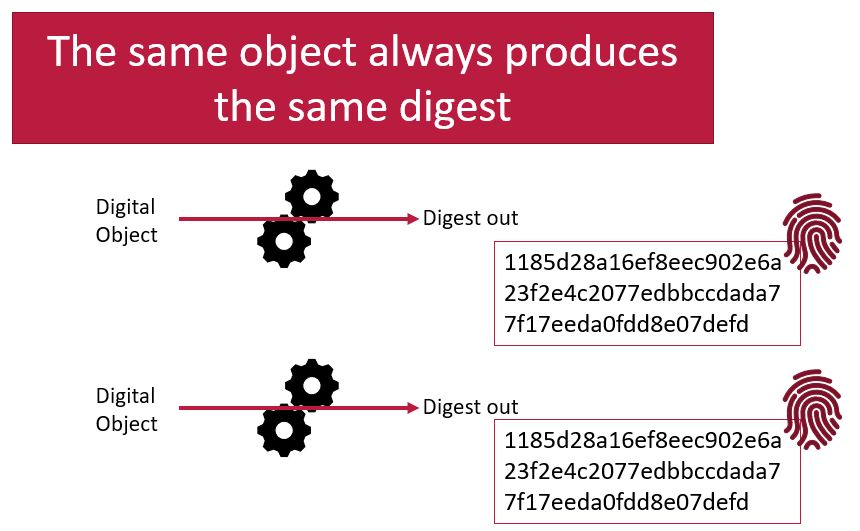
Hashing functions are reproducible
A hashing function will always produce the same digest from the same digital input. This means digests are very reproducible. If you are told what digest to expect when given an digital object, and then you calculate the digest yourself and compare them you can be certain that if the digests are the same, then you have received the original object as expected. If the digests are different, then you know there is a problem somewhere. The digital object you have received is not the one you expected to get. Very slight differences in the digital object (such as adding a single character) will result in drastically different digests.

SAIDs are digests with additional steps
A self-addressing identifier (SAID) is a digest that is embedded into the object it is a hash of. It is now a digest that self-references.
But wait a minute you say! As soon as you add the digest, then the object changes, and therefore the digest changes. This is true. That is why a SAID is digest with a few more steps. When a computer program calculates a SAID it puts a bunch of #’s in the digital object where the SAID is supposed to appear. Then the digest is calculated and that digest replaces the #’s. When you want to verify the SAID, you take out the digest, replace it with #’s, calculate the digest and compare it to the original digest.
A SAID is a digest and it is inserted into a document following reproducible steps. Those who are really into the details can read this in-depth blog posting about the nuances of SAID calculations (and it goes really into the details which can be important to know for implementers!). Users don’t need to know this level of detail but it is important to know it exists.
Using SAIDs
The use of content-addressable identifiers, such as SAIDs, plays a crucial role in ensuring reproducibility. In research workflows, it can be difficult to confirm that a cited digital object is identical to the one originally used. This challenge increases over time as verifying the authenticity of the original object becomes more difficult. By referencing digital objects like schemas with SAIDs, researchers can confidently reproduce workflows using the authentic, original objects. When the SAID in the workflow matches the calculated SAID of the retrieved object, the workflow is verified, enhancing research reproducibility and promoting FAIR research practices.
Conclusion
Content-addressable identifiers like SAIDs are key to ensuring reproducibility in research. By using SAIDs, researchers can confidently reproduce workflows with authentic artifacts, enhancing reproducibility and supporting FAIR practices.
Written by Carly Huitema