ORCID and Decentralized Identifiers
On November 19th, Carly Huitema presented (YouTube link) at the Trust over IP 5-Year Symposium on emerging opportunities to use ORCID as a trust registry to help build secure, verifiable research data spaces. As research becomes increasingly digital and distributed, identity plays a central role in how data is created, shared, and validated. ORCID is already foundational to this ecosystem, and new standards such as Decentralized Identifiers (DIDs) open the door to extending its function beyond its original scope.
ORCID’s Existing Role in Trust and Attribution
For more than a decade, ORCID has provided the research community with a simple but essential service: a persistent, globally unique identifier for every researcher. ORCID IDs sit at the centre of scholarly workflows, connecting people to publications, datasets, affiliations, peer reviews, grants, and contributions.
ORCID IDs reduce ambiguity, streamline reporting, and support better attribution. Because ORCID records are self-maintained, researchers can manage their own scholarly identities while benefiting from integrations with publishers, repositories, and institutions.
One important feature is ORCID’s use of trust signals. When an external organization—such as a university or publisher—adds data to a researcher’s ORCID record, a green check mark appears. This indicates that the information was supplied by a trusted, authenticated source rather than by the researcher alone. These verified entries help create a more authoritative identity record, making ORCID a dependable reference point throughout the research landscape.
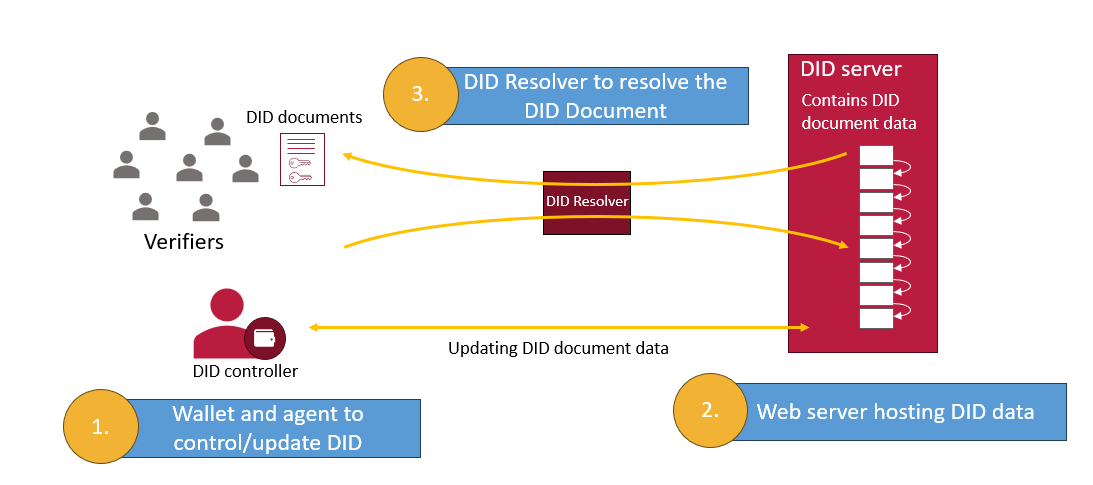
Why Bring Decentralized Identifiers Into the Picture?
The W3C’s Decentralized Identifier (DID) standard introduces cryptographically verifiable identifiers designed for secure digital interactions. Unlike traditional identifiers, a DID resolves to a DID Document, which contains:
-
Authentication keys — for proving control of the identifier.
-
Assertion keys — for signing statements such as dataset provenance records.
-
Key agreement keys — for establishing encrypted communication channels.
-
Service endpoints — for interacting with the DID subject or associated services.
The underlying storage of DID data varies depending on the DID method. It may be anchored in distributed ledgers, file systems, websites, or other registries. More than 200 DID methods exist, all interoperable through the same resolution model.
These keys provide practical capabilities:
-
Authenticate into systems using cryptographic proofs.
-
Sign datasets, workflows, and research outputs.
-
Securely transfer data using encrypted channels.
-
Support machine-to-machine operations with verifiable identity.
This aligns closely with the needs of modern research data ecosystems.
Two Proposals: How ORCID Could Support DIDs
Carly’s presentation introduced two possible integration models for combining ORCID with DIDs.
Proposal 1: Researchers List Their DIDs Within ORCID
The simplest model is allowing researchers to store one or more DIDs in their ORCID profile. ORCID remains the authoritative registry for researcher identity, while DIDs provide a layer of cryptographic capability.
This approach would enable:
Provenance Tracking
Researchers could sign datasets, computational workflows, or experimental logs using their DID keys, enabling verifiable provenance across repositories and platforms.
Authentication
DID authentication keys could be used for secure, passwordless login to research infrastructure—HPC clusters, repositories, cloud notebooks, and more.
Secure Data Transfer
Key agreement keys and service endpoints could support encrypted communication channels for sensitive or controlled-access data.
Building Data Spaces on Existing Keys
Research data spaces could use DID information listed in ORCID as a ready-made trust layer, without requiring a separate identity infrastructure.
This model preserves ORCID’s role while extending the capabilities of researcher identifiers.
Proposal 2: ORCID Hosts Full DID Infrastructure
A second, more ambitious additional option is for ORCID to operate DID infrastructure directly. In this model, ORCID could:
-
Allow researchers to create DIDs in addition to listing them.
-
Issue DIDs using DID methods suited for web publication (e.g.,
did:webvh,did:webs). -
Provide self-certifying identifiers with key pre-rotation support.
-
Maintain verifiable histories and cryptographic proofs of key and document changes.
-
Support witnesses or watchers that monitor DID updates.
-
Publish DID Documents via the ORCID registry for portability and persistence.
This would bootstrap more secure research data spaces by giving the entire ecosystem access to standardized, interoperable, verifiable researcher identifiers backed by ORCID’s trust framework.
This technology is freely available as open source tooling either from the Government of British Columbia (DID:webvh) or the KERI Foundation (DID:webs) and could be hosted by any organization (including ADC). The advantage of DIDs are that they are decentralized and can be operated by many different entities, and even used in combination for multi-key security.
Toward a More Verifiable Research Ecosystem
ORCID already plays a central role in identity and attribution. Adding support for Decentralized Identifiers—whether simply listed in profiles or fully hosted by ORCID, ADC or any other research data space – would expand its capabilities to include authentication, digital signatures, secure communication, and cryptographically verifiable provenance.
As research data spaces continue to develop, these capabilities become essential. ORCID’s existing trust signals, combined with DID-based cryptographic assurance, could form a powerful foundation for next-generation research infrastructure—linking people, systems, and data through verifiable, interoperable digital identity.
For further reference about these technologies check out the educational short videos at Bite Size Trust.
Written by Carly Huitema