Decentralization and Research
What does it mean for research to be decentralized? And how does this relate to ADC? I will use Learning Digital Identity (see also this blog post by the author Phil Windley) for definitions as I think it does the best job.
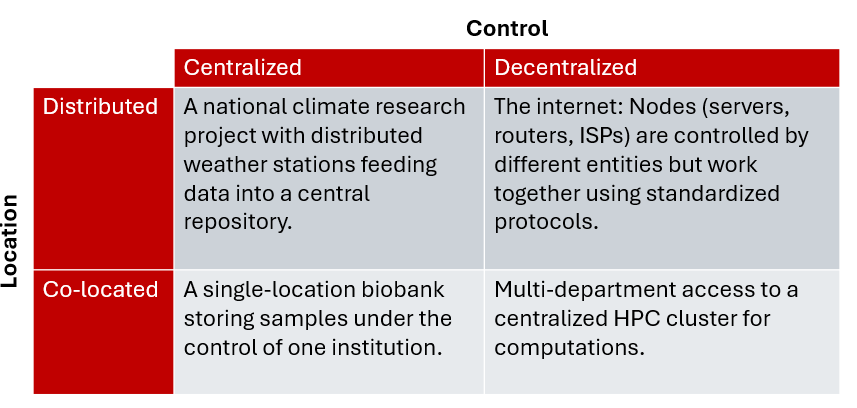
Centralized – Decentralized axis: This axis describes the control of the system. Is the system under the control of a single entity or multiple entities?
Distributed – Co-located axis: This axis describes the location of the system.
Here are some examples:
Co-Located and Centralized
- Examples:
- A standalone server in a data center managed by a single company.
- A single-location biobank storing samples under the control of one institution.
- Characteristics:
- All components are physically or logically co-located.
- Single entity has full control, making coordination simpler.
Co-Located and Decentralized
- Examples:
- A shared core facility in a research institution, such as a microscopy center used by multiple research groups.
- Multi-department access to a centralized HPC cluster for computations.
- Characteristics:
- Components are co-located physically or logically.
- Coordination requires agreements or standards between entities.
Distributed and Centralized
- Examples:
- A research network where one institution operates a centralized database pulling data from distributed studies.
- A cloud platform like AWS or Google Cloud, where distributed servers across the globe are controlled by a single organization.
- A national climate research project with distributed weather stations feeding data into a central repository.
- Characteristics:
- Components are geographically or logically distributed.
- Centralized control simplifies governance but requires robust coordination tools.
Distributed and Decentralized
- Examples:
- The internet: Nodes (servers, routers, ISPs) are controlled by different entities but work together using standardized protocols.
- Blockchain networks like Bitcoin or Ethereum, where no single entity controls all nodes.
- International collaborations like the Large Hadron Collider (LHC), where experiments are distributed across institutions worldwide and no single entity has full control.
- Characteristics:
- Infrastructure and activities are distributed among many entities.
- Coordination is achieved through agreements, protocols, and shared governance, often requiring significant effort to maintain interoperability
Implications
In general, many aspects of research are distributed and decentralized. Health data often has rules about where it can be stored and shared ensuring it will always be co-located. Different researchers work together on projects without a central governance authority that can determine the work of its members. Centralization and co-location of resources can be very useful, with instances of groups coming together to share collective benefits. However, even these nodes of centralization will not join a single platform of all research data run by a single organization. Imagine how successful the World Wide Web would have been if the design had been to build a single server to host all the webpages and a single governance authority to coordinate and approve all the work?
At Agri-food Data Canada we recognize the reality of research, that it needs significant coordination through shared standards and protocols. Indeed, the FAIR principles; that digital objects to be more Findable, Accessible, Interoperable and Reusable (FAIR), supports more efficient and better decentralized and distributed systems. ADC is supporting the development of better standards and protocols and improving decentralized and distributed research by following the FAIR principles and producing tools such as the Semantic Engine. The Semantic Engine helps users write better, machine-readable schemas that can be used across the ecosystem by any participant, helping to maintain data interoperability and contributing to data reuse.
The Semantic Engine also embeds the use of digests into its research data objects. These digests (specifically, Self Addressing IDentifiers or SAIDs) are an important feature of a decentralized and distributed research data ecosystem because no central authority controls the issuance of SAIDs and they can be used throughout the entire research ecosystem while maintaining their meaning. Read more about this in an upcoming blog post!
Written by Carly Huitema