Decentralization and digests
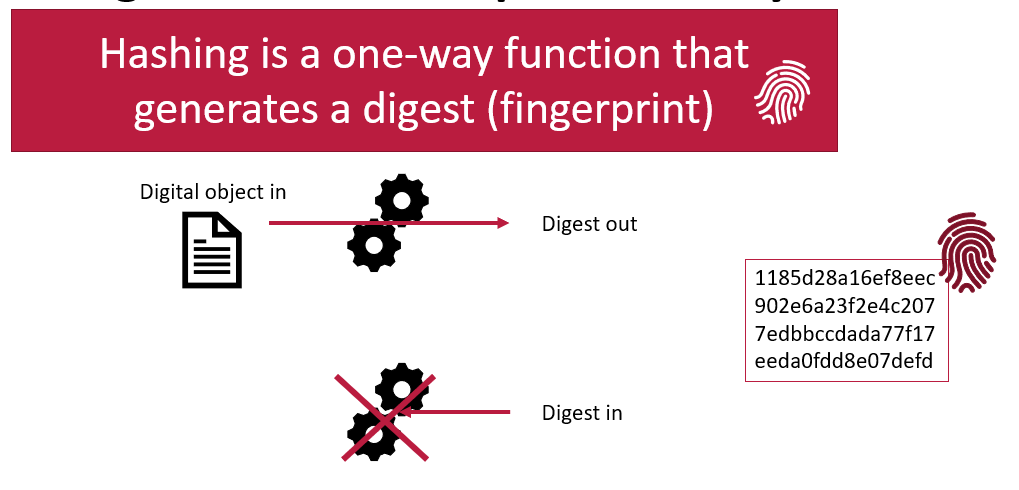
Digests as identifiers
Overlays Capture Architecture (OCA) uses a type of digest called SAIDs (Self-Addressing IDentifiers) as identifiers. Digests are essentially digital fingerprints which provide an unambiguous way to identify a schema. Digests are calculated directly from the schema’s content, meaning any change to the content results in a new digest. This feature is crucial for research reproducibility, as it allows you to locate a digital object and verify its integrity by checking if its content has been altered. Digests ensure trust and consistency, enabling accurate tracking of changes. For a deeper dive into how digests are calculated and their role in OCA, we’ve written a detailed blog post exploring digest use in OCA.
Digests are not limited to schemas, digests can be calculated and used as an identifier for any type of digital research object. While Agri-food Data Canada (ADC) is using digests initially for schemas generated by the Semantic Engine (written in OCA), we envision digests to be used in a variety of contexts, especially for the future identification of research datasets. This recent data challenge illustrates the current problem with tracing data pedigree. If research papers were published with digests of the research data used for the analysis the scholarly record could be better preserved. Even data held in private accounts could be verified that they contain the data as it was originally used in the research study.
Decentralized research
The research ecosystem is in general a decentralized ecosystem. Different participants and organizations come together to form nodes of centralization for collaboration (e.g. multiple journals can be searched by a central index such as PubMed), but in general there is no central authority that controls membership and outputs in a similar way that a government or company might. Read our blog post for a deeper dive into decentralization.
Centralized identifiers such as DOI (Digital Object Identifier) are coordinated by a centrally controlled entity and uniqueness of each identifier depends on the centralized governance authority (the DOI Foundation) ensuring that they do not hand out the same DOI to two different research papers. In contrast, digests such as SAIDs are decentralized identifiers. Digests are a special type of identifier in that no organization handles their assignment. Digests are calculated from the content and thus require no assignment from any authority. Calculated digests are also expected to be globally unique as the chance of calculating the same SAID from two different documents is vanishingly small.
Digests for decentralization
The introduction of SAIDs enhances the level of decentralization within the research community, particularly when datasets undergo multiple transformations as they move through the data ecosystem. For instance, data may be collected by various organizations, merged into a single dataset by another entity, cleaned by an individual, and ultimately analyzed by someone else to answer a specific research question. Tracking the dataset’s journey—where it has been and who has made changes—can be incredibly challenging in such a decentralized process.
By documenting each transformation and calculating a SAID to uniquely identify the dataset before and after each change, we have a tool that helps us gain greater confidence in understanding what data was collected, by whom, and how it was modified. This ensures a transparent record of the dataset’s pedigree.
In addition, using SAIDs allows for the assignment of digital rights to specific dataset instances. For example, a specific dataset (identified and verified with a SAID) could be licensed explicitly for training a particular AI model. As AI continues to expand, tracking the provenance and lineage of research data and other digital assets becomes increasingly critical. Digests serve as precise identifiers within an ecosystem, enabling governance of each dataset component without relying on a centralized authority.
Traditionally, a central authority has been responsible for maintaining records—verifying who accessed data, tracking changes, and ensuring the accuracy of these records for the foreseeable future. However, with digests and digital signatures, data provenance can be established and verified independently of any single authority. This decentralized approach allows provenance information to move seamlessly with the data as it passes between participants in the ecosystem, offering greater flexibility and opportunities for data sharing without being constrained by centralized infrastructure.
Conclusion
Self-Addressing Identifiers such as those used in Overlays Capture Architecture (OCA), provide unambiguous, content-derived identifiers for tracking and governing digital research objects. These identifiers ensure data integrity, reproducibility, and transparency, enabling decentralized management of schemas, datasets, and any other digital research object.
Self-Addressing Identifiers further enhance decentralization by allowing data to move seamlessly across participants while preserving its provenance. This is especially critical as AI and complex research ecosystems demand robust tracking of data lineage and usage rights. By reducing reliance on centralized authorities, digests empower more flexible, FAIR, and scalable models for data sharing and governance.
Written by Carly Huitema