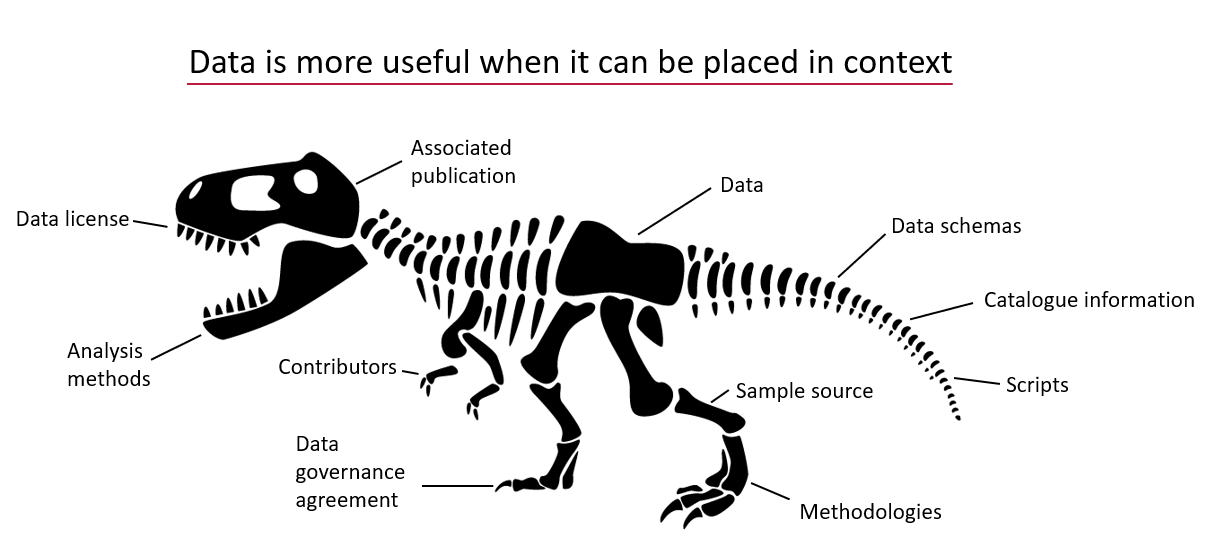
Data Needs Context
Understanding Data Requires Context
Data without context is challenging to interpret and utilize effectively. Consider an example: raw numbers or text without additional information can be ambiguous and meaningless. Without context, data fails to convey its full value or purpose.

By providing additional information, we can place data within a specific context, making it more understandable and actionable – more FAIR. This context is often supplied through metadata, which is essentially “data about data.” A schema, for instance, is a form of metadata that helps define the structure and meaning of the data, making it clearer and more usable.
The Role of Schemas in Contextualizing Data
A data schema is a structured form of metadata that provides crucial context to help others understand and work with data. It describes the organization, structure, and attributes of a dataset, allowing data to be more effectively interpreted and utilized.

A well-documented schema serves as a guide to understanding the dataset’s column labels (attributes), their meanings, the data types, and the units of measurement. In essence, a schema outlines the dataset’s structure, making it accessible to users.
For example, each column in a dataset corresponds to an attribute, and a schema specifies the details of that column:
- Units: What units the data is measured in (e.g., meters, seconds).
- Format: What format the data should follow (e.g., date formats).
- Type: Whether the data is numerical, textual, boolean etc.
The more features included in a schema to describe each attribute, the richer the metadata, and the easier it becomes for users to understand and leverage the dataset.

Writing and Using Schemas
When preparing to collect data—or after you’ve already gathered a dataset—you can enhance its usability by creating a schema. Tools like the Semantic Engine can help you write a schema, which can then be downloaded as a separate file. When sharing your dataset, including the schema ensures that others can fully understand and use the data.
Reusing and Extending Schemas
Instead of creating a new schema for every dataset, you can reuse existing schemas to save time and effort. By building upon prior work, you can modify or extend existing schemas—adding attributes or adjusting units to align with your specific dataset requirements.
One Schema for Multiple Datasets
In many cases, one schema can be used to describe a family of related datasets. For instance, if you collect similar data year after year, a single schema can be applied across all those datasets.
Publishing schemas in repositories (e.g., Dataverse) and assigning them unique identifiers (such as DOIs) promotes reusability and consistency. Referencing a shared schema ensures that datasets remain interoperable over time, reducing duplication and enhancing collaboration.
Conclusion
Context is essential to making data understandable and usable. Schemas provide this context by describing the structure and attributes of datasets in a standardized way. By creating, reusing, and extending schemas, we can make data more accessible, interoperable, and valuable for users across various domains.
Written by Carly Huitema