Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund
Semantic objects
Maintaining clean, consistent data remains one of the biggest challenges in data management. Entry codes—also known as picklists—have long played a key role in improving data quality by standardizing how information is captured. Building on this foundation, a new Entry Code Library feature has been introduced in the Semantic Engine schema writer, making it easier than ever to reuse proven standards and reduce errors at the point of data entry.
The Value of Entry Codes (Picklists)
Entry codes provide a structured alternative to free-text data entry. Instead of allowing users to manually type values, entry codes limit input to a predefined list of acceptable options. This approach helps:
- Prevent spelling mistakes and inconsistent terminology
- Ensure uniform data across datasets and projects
- Improve searchability, aggregation, and downstream analysis
By capturing standardized codes rather than variable text, datasets become more reliable, interoperable, and easier to maintain over time.
Introducing the Entry Code Library
Based on direct user feedback, the Semantic Engine team has introduced an Entry Code Library to streamline schema creation and encourage reuse of existing work.
When defining a variable in the schema writer, users who select List as their initial data type now gain access to a premade library of entry codes.
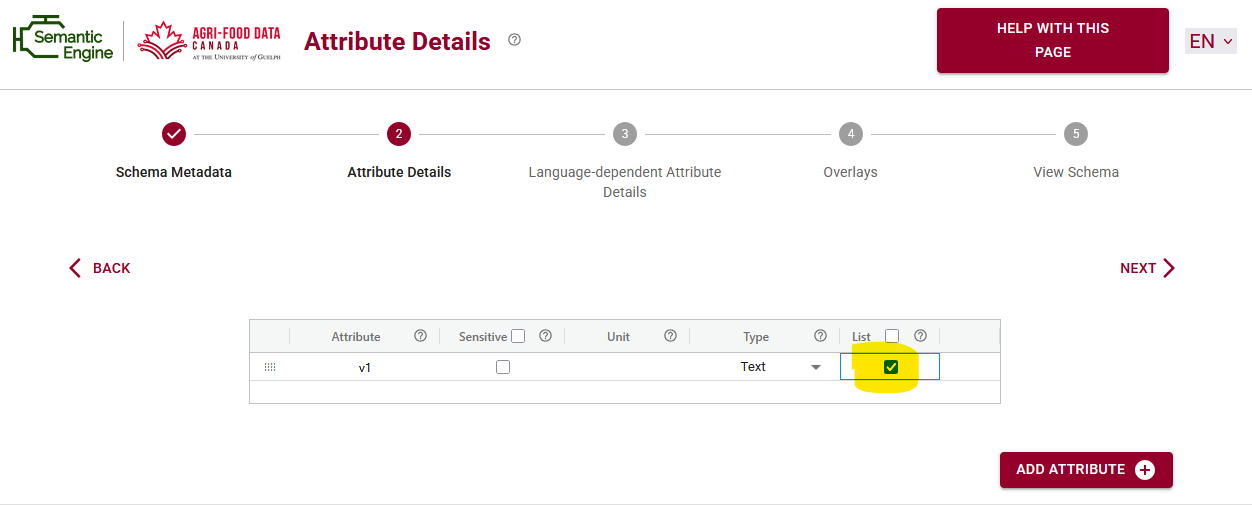
Rather than building a list from scratch each time, you can browse and search the library for existing code lists that meet your needs.
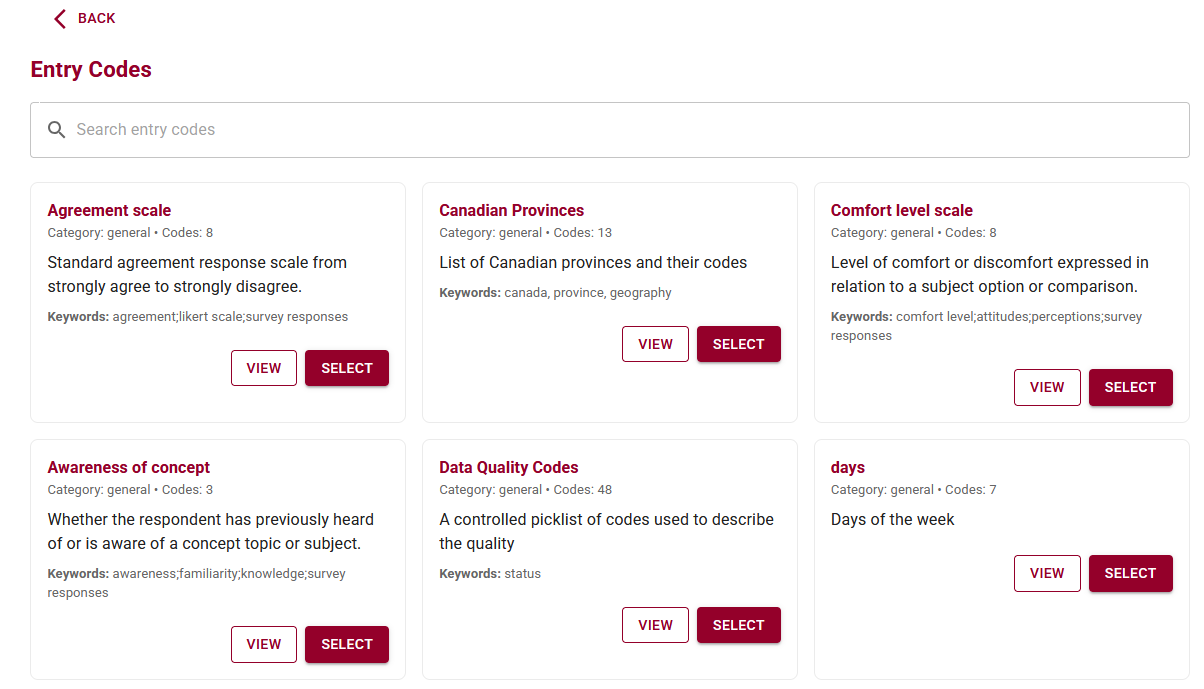
Search, Reuse, and Align with Standards
The Entry Code Library is designed to save time and improve consistency by helping users:
- Search for commonly used entry code lists
- Reuse established vocabularies and standards
- Avoid duplication of effort across projects
- Reduce data cleanup caused by inconsistent entry values
By leveraging shared entry code lists, datasets across teams and domains can align more easily, improving overall data interoperability.
Contributing to the Library
The Entry Code Library is a growing resource. If you have created—or identified—a code list that you believe would be valuable to others, we encourage you to contribute.
If you see a list you would like added to the library, please contact us at adc@uoguelph.ca.
Your contributions help build a stronger, more reusable ecosystem for high-quality data entry.
Moving Toward Cleaner Data by Design
Entry codes have always been a powerful tool for enforcing consistency at the point of data capture. With the introduction of the Entry Code Library in the Semantic Engine schema writer, users now have even greater support for creating standardized, reusable, and error-resistant schemas.
By combining structured entry codes with shared libraries and community input, data quality improves not after collection—but from the very beginning.
Written by Carly Huitema
There are many high quality vocabularies, taxonomies and ontologies that researchers can use and incorporate into their schemas to help improve the quality and accuracy of their data. We’ve already talked about ontologies here in this blog but here we go into a few more details.
Semantic Objects
Vocabularies, ontologies, and taxonomies are examples of semantic objects or knowledge organization systems (KOS). These tools help structure, standardize, and manage information within a particular domain to ensure consistency, accuracy, and interoperability. They provide frameworks for organizing data, defining relationships between concepts, and enabling machines to understand and process information effectively.
Key Roles of Semantic Objects:
- Standardization: Encourage consistent use of terms across datasets and systems.
- Interoperability: Improve data sharing and integration by aligning different systems with shared meanings.
- Data Quality: Improve accuracy and reduce ambiguity in data collection and analysis.
- Machine-Readability: Enable automation, semantic search, and advanced data processing. Prepare data for AI.
These tools are foundational in disciplines such as bioinformatics, healthcare, and agriculture, contributing to better data management and enhanced research outcomes.
Vocabularies: A set of terms and their definitions used within a particular domain or context to ensure consistent communication and understanding.
Example: A glossary of medical terms.
Taxonomies: A hierarchical classification system that organizes terms or concepts into parent-child relationships, typically used to categorize information.
Example: The classification of living organisms into kingdom, phylum, class, order, family, genus, and species.
Ontologies: A formal representation of knowledge within a domain, including the relationships between concepts, often expressed in a way that can be processed by computers.
Example: The Gene Ontology, which describes gene functions and their relationships in a structured form.
Examples of terms
There are many vocabularies, taxonomies and ontologies (semantic objects) that you can use, or already using. For example, many researchers in genetics are familiar with GO, an ontology for genes. PubMed improves your search by using MeSH (Medical Subject Headings) as the NLM controlled vocabulary thesaurus used for indexing articles. The FoodON is a farm to fork ontology with many terms all related to food production including agriculture and processing.
Read more about semantic objects such as vocabularies, taxonomies and ontologies including how to select the right one for you at the FAIR cookbook.
Use your list of terms
You can use controlled lists of terms (derived from semantic objects) in your data collection in order to standardize the information you are recording. This is well understood for organism taxonomy (not making up new names when you are specifically describing a species) and in genetics (using standard gene names from an ontology such as GO). There are many other controlled terms you can find as well to help standardize your data collection and improve interoperability by incorporating controlled terms into a schema.
How to use terms in a schema
After you have identified a source of terms you need to get this information into a schema. The easiest way to do this using the Semantic Engine is to create a terms list as a .csv file from your source. Give your term list headings; for example terms from the GO ontology are usually fairly esoteric GO numbers and these can be the entry codes whereas more friendly labels can be given (in multiple languages) which can help with data entry. The entry codes are the information that is added to your data, so when it comes time to perform analysis your data will consist of the entry codes (and not the label).
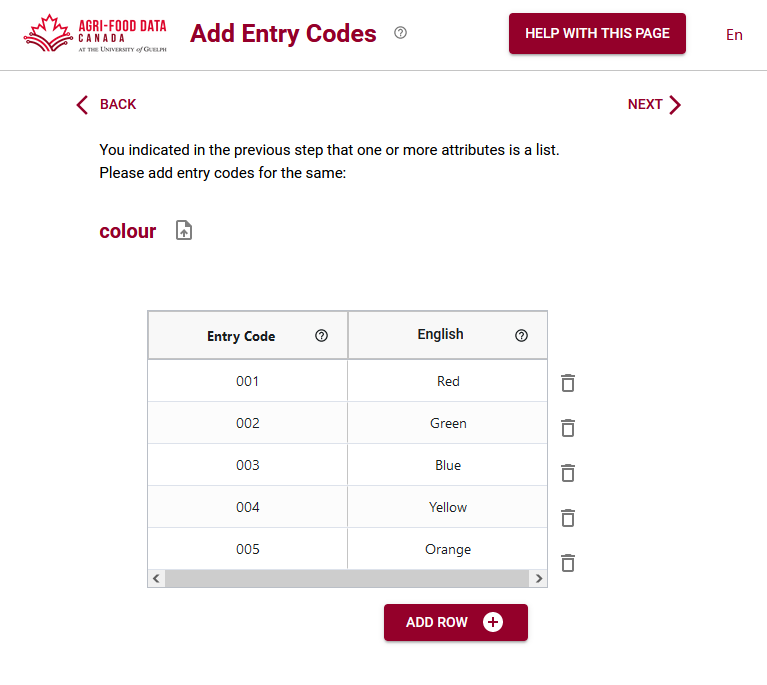
Incorporating high-quality vocabularies, taxonomies, and ontologies into your schemas is an essential step to enhance data quality, consistency, and interoperability. Vocabularies provide standardized definitions for domain-specific terms, taxonomies offer hierarchical classification systems, and ontologies formalize knowledge structures with defined relationships, enabling advanced data processing and analysis. Examples such as GO, MeSH, and FoodON demonstrate how these semantic objects are already widely used in fields like genetics, healthcare, and food production.
By leveraging controlled lists of terms derived from these resources, researchers can ensure standardized data collection, improving both the accuracy and reusability of their datasets. Creating term lists in machine-readable formats like .csv files allows seamless integration into schemas, facilitating better data management and fostering compliance with FAIR data principles.
Written by Carly Huitema