Funding for Agri-food Data Canada is provided in part by the Canada First Research Excellence Fund
FAIR
When data entry into an Excel spreadsheet is not standardized, it can lead to inconsistencies in formats, units, and terminology, making it difficult to interpret and integrate research data. For instance, dates entered in various formats, inconsistent use of abbreviations, or missing values can give problems during analysis leading leading to errors.
Organizing data according to a schema—essentially a predefined structure or set of rules for how data should be entered—makes data entry easier and more standardized. A schema, such as one written using the Semantic Engine, can define fields, formats, and acceptable values for each column in the spreadsheet.
Using a standardized Excel sheet for data entry ensures uniformity across datasets, making it easier to validate, compare, and combine data. The benefits include improved data quality, reduced manual cleaning, and streamlined data analysis, ultimately leading to more reliable research outcomes.
After you have created a schema using the Semantic Engine, you can use this schema (the machine-readable version) to generate a Data Entry Excel.

When you open your Data Entry Excel you will see it consists of two sheets, one for schema description and one for the entry for data. The schema description sheets takes information from the schema that was uploaded and puts it into an information table.
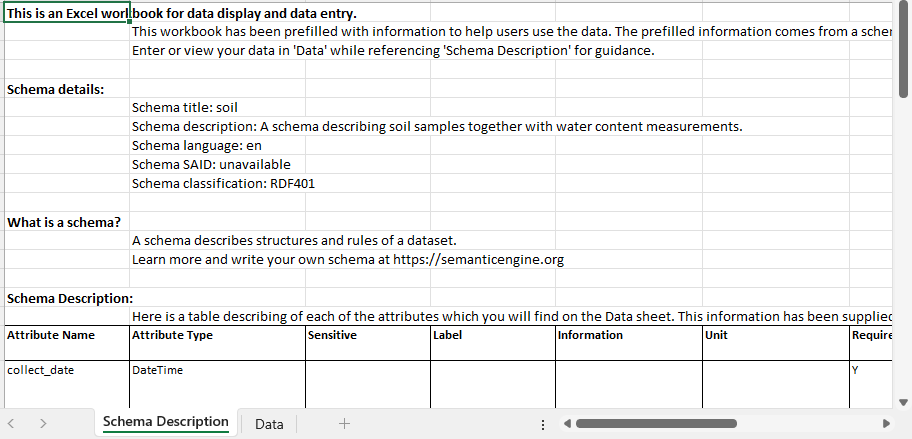
At the very bottom of the information table are listed all of the entry code lists from the schema. This information is used on the data entry side for populating drop-down lists.
On the data entry sheet of the Data Entry Excel you can find the pre-labeled columns for data entry according to the rules of your schema. You can rearrange the columns as you want, and you can see that the Data Entry Excel comes with prefilled dropdown lists from those variables (attributes) that have entry codes. There is no dropdown list if the data is expected to be an array of entries or if the list is very long. As well, you will need to wrestle with Excel time/date attributes to have it appear according to what is documented in the schema description.
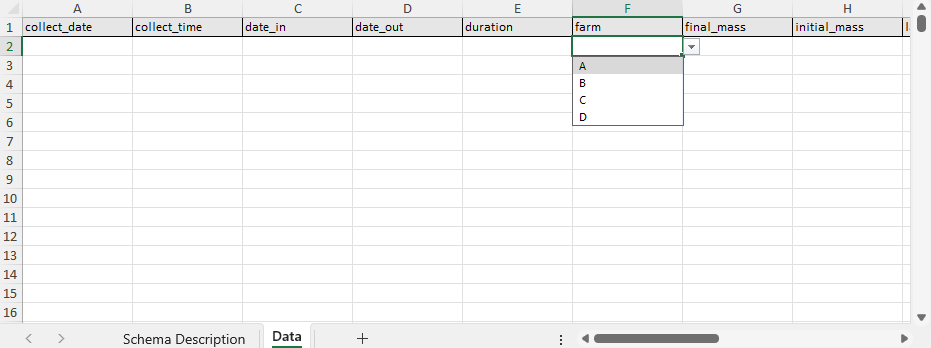
There is no verification of data in Excel that is set up when you generate your Data Entry Excel apart from the creation of the drop-down lists. For data verification you can upload your Data Entry Excel to the Data Verification tool available on the Semantic Engine.
Using the Data Entry Excel feature lets you put your data schemas to use, helping you document and harmonize your data. You can store your data in Excel sheets with pre-filled information about what kind of data you are collecting! You can also use this to easily collect data as part of a larger project where you want to combine data later for analysis.
Written by Carly Huitema
Alrighty – so you have been learning about the Semantic Engine and how important documentation is when it comes to research data – ok, ok, yes documentation is important to any and all data, but we’ll stay in our lanes here and keep our conversation to research data. We’ve talked about Research Data Management and how the FAIR principles intertwine and how the Semantic Engine is one fabulous tool to enable our researchers to create FAIR research data.
But… now that you’ve created your data schema, where can you save it and make it available for others to see and use? There’s nothing wrong with storing it within your research group environment, but what if there are others around the world working on a related project? Wouldn’t it be great to share your data schemas? Maybe get a little extra reference credit along your academic path?
Let me walk you through what we have been doing with the data schemas created for the Ontario Dairy Research Centre data portal. There are 30+ data schemas that reflect the many data sources/datasets that are collected dynamically at the Ontario Research Dairy Centre (ODRC), and we want to ensure that the information regarding our data collection and data sources is widely available to our users and beyond by depositing our data schemas into a data repository. We want to encourage the use and reuse of our data schemas – can we say R in FAIR?
Storing the ADC data schemas
Agri-food Data Canada(ADC) supports, encourages, and enables the use of national platforms such as Borealis – Canadian Dataverse Repository. The ADC team has been working with local researchers to deposit their research data into this repository for many years through our OAC Historical Data project. As we work on developing FAIR data and ensuring our data resources are available in a national data repository, we began to investigate the use of Borealis as a repository for ADC data schemas. We recognize the need to share data schemas and encourage all to do so – data repositories are not just for data – let’s publish our data schemas!
If you are interested in publishing your data schemas, please contact adc@uoguelph.ca for more information. Our YouTube series: Agri-food Data Canada – Data Deposits into Borealis (Agri-environmental Data Repository) will be updated this semester to provide you guidance on recommended practices on publishing data schemas.
Where is the data schema?
So, I hope you understand now that we can deposit data schemas into a data repository – and here at ADC, we are using the Borealis research data repository. But now the question becomes – how, in the world do I find the data schemas? I’ll walk you through an example to help you find data schemas that we have created and deposited for the data collected at the ODRC.
- Visit Borealis (the Canadian Dataverse Repository) or the data repository for research data.
- In the search box type: Milking data schema
- You will get a LOT of results (152, 870+) so let’s try that one again
- Go back to the Search box and using boolean searching techniques in the search box type: “data schema” AND milking
- Now you should have around 35 results – essentially any entry that has the words data schema together and milking somewhere in the record
- From this list select the entry that matches the data you are aiming to collect – let’s say the students were working with the cows in the milking parlour. So you would select ODRC data schema: Milk parlour data


Now you have a data schema that you can use and share among your colleagues, classmates, labmates, researchers, etc…..
Remember to check out what you else you can do with these schemas by reading about all about Data Verification.
Summary
A quick summary:
- I can deposit my data schemas into a repository – safe keeping, sharing, and getting academic credit all in one shot!
- I can search for a data schema in a repository such as Borealis
- I can use a data schema someone else has created for my own data entry and data verification!
Wow! Research data life is getting FAIRer by the day!
![]()
What do you do when you’ve collected data but you need to also include notes in the data. Do you mix the data together with the notes?
Here we build on our previous blog post describing data quality comments with worked examples.
An example of quality comments embedded into numeric data is if you include values such as NULL or NA when you have a data table. Below are some examples of datatypes being assigned to different attributes (variables v1-v8). You can see in v5 that there is are numeric measurements values mixed together with quality notations such as NULL, NA, or BDL (below detection limit).
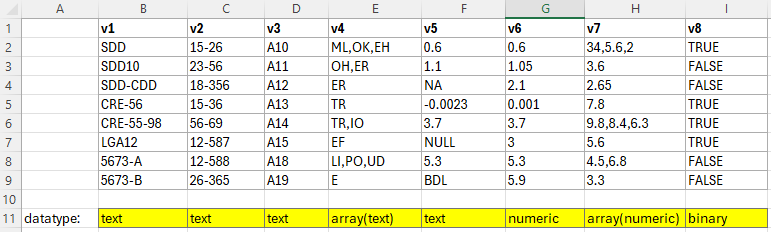
Technically, this type of data would be given the datatype of text when using the Semantic Engine. However, you may wish to use v5 as a numeric datatype so that you can perform analysis with it. You could delete all the text values, but then you would be losing this important data quality information.
As we described in a previous blog post, one solution to this challenge is to add quality comments to your dataset. How you would do this is demonstrated in the next data example.
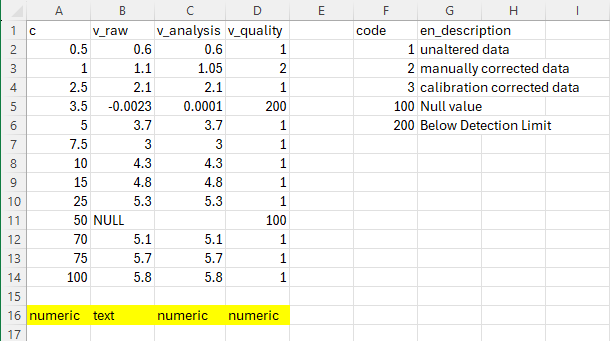
In this next example there are two variables: c and v. Variable v contains a mixture of numeric values and text.
step 1: Rename v to v_raw. It is good practice to always keep raw data in its original state.
step 2: copy the values into v_analysis and here you can remove any text values and make other adjustments to values.
step 3: document your adjustments in a new column called v_quality and using a quality code table.
The quality code table is noted on the right of the data. When using the Semantic Engine you would put this in a separate .csv file and import it as an entry code list. You would also remove the highlighted dataypes (numeric, text etc.) which don’t belong in the dataset but are written here to make it easier to understand.
You can watch the entire example being worked through using the Semantic Engine in this YouTube video. Note that even without using the Semantic Engine you can annotate data with quality comments, the Semantic Engine just makes the process easier.
Written by Carly Huitema
How to Use ISO 8601 Duration Format
The ISO 8601 duration format allows you to represent durations of time in a standardized way. For example, if your data records contain a mixture of duration (e.g. 3 days, 4 months, 1 year etc.) you can represent all of these values using the ISO standard duration. Read more about using the ISO date/time standard for your other data formats.
The ISO standard duration format is `PnYnMnDTnHnMnS`, where:
– `P` indicates the period (required).
– `nY` indicates the number of years.
– `nM` indicates the number of months.
– `nW` indicates the number of weeks.
– `nD` indicates the number of days.
– `T` separates the date and time components.
– `nH` indicates the number of hours.
– `nM` indicates the number of minutes.
– `nS` indicates the number of seconds.
Examples
One Year, Two Months, and Three Days:
– Format: `P1Y2M3D`
Six Months:
– Format: `P6M`
Four Weeks:
– Format: `P4W`
Three Hours, Fifteen Minutes, and Thirty Seconds:
– Format: `PT3H15M30S`
Two Years and Six Months:
– Format: `P2Y6M`
One Day and Twelve Hours:
– Format: `P1DT12H`
Forty-Five Seconds:
– Format: `PT45S`
Two Days, Three Hours, Four Minutes, and Five Seconds:
– Format: `P2DT3H4M5S`
One Year, Two Months, Three Days, Four Hours, Five Minutes, and Six Seconds:
– Format: `P1Y2M3DT4H5M6S`
Tips
– The `P` is mandatory and indicates that the following string defines a period.
– The `T` is used to separate the date and time components.
– Any of the components (`Y`, `M`, `W`, `D`, `H`, `M`, `S`) can be omitted if they are not needed.
– Ensure that the order of components is preserved: years, months, weeks, days, hours, minutes, and seconds.
When writing your schema using Semantic Engine duration is supported as a data format. Choose DateTime as a datatype to have this option available when adding a format feature.
Using these examples and tips, you can accurately represent various durations in the ISO 8601 format.
Written by Carly Huitema
When submitting a publication to a journal you are often asked to submit data, publish it in a repository, or otherwise make it available. The journals may ask that your data supports FAIR principles (that data is Findable, Accessible, Interoperable and Reusable). You may be asked to submit supplementary data to a generalist or specialist repository, or you may choose to make the data available on request.
More FAIR data
Writing schemas to document your data using the Semantic Engine can help you meet these journal submission goals and requirements. The information documented in a schema (which may also be described as the data dictionary or the dataset metadata) helps your research data be more FAIR.
Documented information makes the data more findable in searches, accessible because people know what is in your datasets and can understand it, interoperable because people don’t need to guess what your data means, what your units are, and how you measured certain variables. All these contribute to improve the reusability of your dataset.
Deposit a schema
When you submit a dataset in any repository you can include the schemas (both the machine-readable .zip/JSON version and the human-readable and archival Readme.txt version) in your submission.
If you only want to make your data available by request you could publish just your schema, giving it a DOI, and referencing it in your publication. This way, anyone who wants to know if your data is useful before requesting it can look at the schema to see if it could contain information that they need.
The Semantic Engine makes it easy to document your schema because it is an easy to follow web interface with prompts and help information which assist you in writing your data schema. Follow our tutorial video to see how easy it is to create your own schema. You can use this documentation when submitting your data to a journal publication so that other people can understand and benefit from your data.
Written by Carly Huitema
Let’s take a little jaunt back to my FAIR posts. Remember that first one? R is for Reusable? Now, it’s one thing to talk about data re-usability, but it’s an entirely different thing to put this into action. Well, here at Agri-food Data Canada or ADC we like to put things into action, or think about it as “putting our money where our mouth is”. Oh my! I’m starting to sound like a billboard – but it’s TIME to show off what we’re doing!
Alrighty – data re-usability. Last time I talked about this, I mentioned the reproducibility crisis and the “fear” of people other than the primary data collector using your data. Let’s take this to the next level. I WANT to use data that has been collected by other researchers, research labs, locales, etc… But now the challenge becomes – how do I find this data? How can I determine whether I want to use it or whether it fits my research question without downloading the data and possibly running some pre-analysis, before deciding to use it or not?
ADC’s Re-usable Data Explorer App
How about our newest application? the Re-usable Data Explorer App? The premise behind this application is that research data will be stored in a data repository, we’ll use Borealis, the Canadian Dataverse Repository for our instance. At the University of Guelph, I have been working with researchers in the Ontario Agricultural College for a few years now, to help them deposit data from papers that have already been published – check out the OAC Historical Data project. There are currently almost 1,500 files that have been deposited representing almost 60 studies. WOW! Now I want to explore what data there is and whether it is applicable to my study.
Let’s visit the Re-usable Data Explorer App and select Explore Borealis at the top of the page. You have the option to select Study Network and Data Review. Select Study Network and be WOWed. You have the option to select a department within OAC or the Historical project. I’m choosing the Historical project for the biggest impact! I also love the Authors option.

Look at how all these authors are linked, just based on the research data they deposited into the OAC historical project! Select an author to see how many papers they are involved with and see how their co-authors link to others and so on.
But ok – where’s the data? Let’s go back and select a keyword. Remember lots of files, means you need a little patience for the entire keyword network to load!! Zoom in to select your keyword of choice – I’ll select “Nitrogen”. Now you will notice that keywords needs some cleaning up and that will happen over the next few iterations of this project. Alright nitrogen appears in 4 studies – let’s select Data Review at the top. Now I need to select one of the 4 studies – I selected the Replication Data for: Long-term cover cropping suppresses foliar and fruit disease in processing tomatoes.
What do I see?
All the metadata – at the moment this comes directly from Borealis – watch for data schemas to pop up here in the future! Let’s select Data Exploration – OOOPS the data is restricted for this study – no go.
Alrighty let’s select another study: Replication Data for: G18-03 – 2018 Greens height fertility trial
Metadata – see it! Let’s try Data exploration – aha! Looking great – select a datafile – anything with a .tab ending – and you will see a listing of the raw data. Check out Data Summary and Data Visualization tabs!

Wow!! This gives me an idea of the relationship of the variables in this dataset and I can determine by browsing these different visualizations and summary statistics whether this dataset fits the needs of my current study – whether I can RE-USE this data!
Last question though – ok I’ve found a dataset I want to use – how do I access it? Easy… Go to the Study Overview tab scroll down to the DOI of the dataset. Click it or copy it into your browser and it will take you to the dataset in the data repository and you can click Access Dataset to view your download options
Data Re-use at my fingertips
Now isn’t that just great! This project came from a real use case scenario and I just LOVE what the team has created! Try it out and let us know what you think or if you run into any glitches!
I’m looking forward to the finessing that will take place over the next year or so – but for now enjoy!!
![]()
Is your data ready to describe using a schema? How can you ensure the fewest hiccups when writing your schema (such as with the Semantic Engine)? What kind of data should you document in your schema and what kinds of data can be left out?
Document data in chunks
When you prepare to describe your data with a schema, try to ensure that you are documenting ‘data chunks’, which can be grouped together based on function. Raw data is a type of data ‘chunk’ that deserves its own schema. If you calculate or manipulate data for presentation in a figure or as a published table you could describe this using a separate schema.
For example, if you take averages of values and put them in a new column and calculate this as a background signal which you then remove from your measurements which you put in another column; this is an summarizing/analyzing process and is probably a different kind of data ‘chunk’. You should document all the data columns before this analysis in your schema and have a separate table (e.g. in a separate Excel sheet) with a separate schema for manipulated data. Examples of data ‘chunks’ include ‘raw data’, ‘analysis data’, ‘summary data’ and ‘figure and table data’. You can also look to the TIER protocol for how to organize chunks of data through your analysis procedures.
Look for Entry Code opportunities
Entry codes can help you streamline your data entry and improve existing data quality.
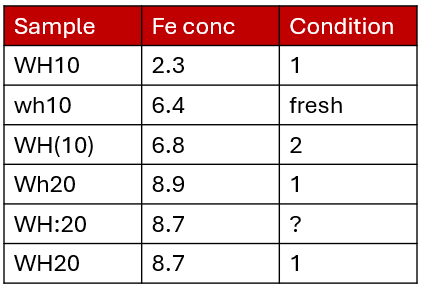
For example, here is a dataset that could benefit from using entry codes. The sample name looks like it would consist of two sample types (WH10 and WH20) but there are multiple ways of writing the sample name. The same thing for condition. You can read our blog post about entry codes which works through the above example. If you have many entry codes you can also import entry codes from other schemas or from a .csv file using the Semantic Engine.
Separate out columns for clarity
Sometimes you may have compressed multiple pieces of information into a single column. For example, your sample identifier might have several pieces of useful information. While this can be very useful for naming samples, you can keep the sample ID and add extra columns where you pull all of the condensed information into separate attributes, one for each ‘fact’. This can help others understand the information coded in your sample names, and also make this information more easily accessible for analysis. Another good example of data that should be separated are latitude and longitude attributes which benefit from being in separate columns.
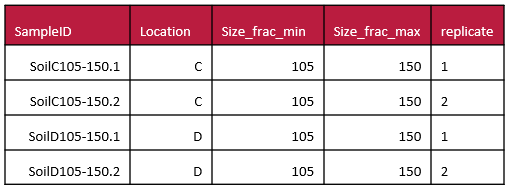
Consider adopting error coding
If your data starts to have codes written in the data as you annotate problems with collection or missing samples, consider putting this information in an adjacent data quality column so that it doesn’t interfere with your data analysis. Your columns of data should contain only one type of information (the data), and annotations about the data can be moved to an adjacent quality column. Read our blog post to learn more about adding quality comments to a dataset using the Semantic Engine.
Look for standards you can use
It can be most helpful if you can find ways to harmonize your work with the community by trying to use standards. For example, there is an ISO standard for date/time values which you could use when formatting these kinds of attributes (even if you need to fight Excel to do so!).
Consider schema reuse
Schemas will often be very specific to a specific dataset, but it can be very beneficial to consider writing your schema to be more general. Think about your own research, do you collect the same kinds of data over and over again? Could you write a single schema that you can reuse for each of these datasets? In research schemas written for reuse are very valuable, such as a complex schema like phenopackets, and reusable schemas help with data interoperability improving FAIRness.
In conclusion, you can do many things to prepare your data for documentation. This will help both you and others understand your data and thinking process better, ensuring greater data FAIRness and higher quality research. You can also contribute back to the community if you develop a schema that others can use and you can publish this schema and give it an identifier such as DOI for others to cite and reuse.
Written by Carly Huitema
How should you organize your files and folders when you start on a research project?
Or perhaps you have already started but can’t really find things.
Did you know that there is a recommendation for that? The TIER protocol will help you organize data and associated analysis scripts as well as metadata documentation. The TIER protocol is written explicitly for performing analysis entirely by scripts but there is a lot of good advice that researchers can apply even if they aren’t using scripts yet.
“Documentation that meets the specifications of the TIER Protocol contains all the data, scripts, and supporting information necessary to enable you, your instructor, or an interested third party to reproduce all the computations necessary to generate the results you present in the report you write about your project.” [TIER protocol]
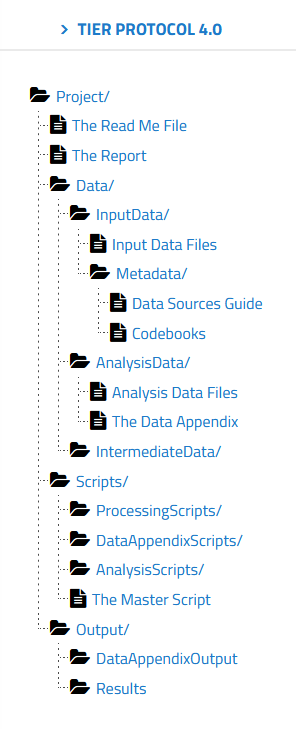
If you go to the TIER protocol website, you can explore the folder structure and read about the contents of each folder. You have folders for raw data, for intermediate data, and data ready for analysis. You also have folders for all the scripts used in your analysis, as well as any associated descriptive metadata.
You can use the Semantic Engine to write the schema metadata, the data that describes the contents of each of your datasets. Your schemas (both the machine-readable format and the human-readable .txt file) would go into metadata folders of the TIER protocol. The TIER protocol calls data schemas “Codebooks”.
Remember how important it is to never change raw data! Store your raw collected data before any changes are made in the Input Data Files folder and never! ever! change the raw data. Make a copy to work from. It is most valuable when you can work with your data using scripts (and stored in the scripts folder of the TIER protocol) rather than making changes to the data directly via (for example) Excel. Benefits include reproducibility and the ease of changing your analysis method. If you write a script you always have a record of how you transformed your data and anyone who can re-run the script if needed. If you make a mistake you don’t have to painstakingly go back through your data and try and remember what you did, you just make the change in the script and re-run it.
The TIER protocol is written explicitly for performing analysis entirely by scripts. If you don’t use scripts to analyze your data or for some of your data preparation steps you should be sure to write out all the steps carefully in an analysis documentation file. If you are doing the analysis for example in Excel you would document each manual step you make to sort, clean, normalize, and subset your data as you develop your analysis. How did you use a pivot table? How did decide which data points where outliers? Why did you choose to exclude values from your analysis? The TIER protocol can be imitated such that all of this information is also stored in the scripts folder of the TIER protocol.
Even if you don’t follow all the directions of the TIER protocol, you can explore the structure to get ideas of how to best manage your own data folders and files. Be sure to also look at advice on how to name your files as well to ensure things are very clear.
Written by Carly Huitema
Findable
Accessible (where possible)
Interoperable
Reusable
Ah the last Blog post in the series of 4 regading the FAIR principles. The last or the first, depending on how you look at it :). F for Findable! Quick review from the FAIR website:
F1. (Meta)data are assigned a globally unique and persistent identifier
F2. Data are described with rich metadata (defined by R1 below)
F3. Metadata clearly and explicitly include the identifier of the data they describe
F4. (Meta)data are registered or indexed in a searchable resource
As we’ve ventured through the FAIR principles, we’ve highlighted the reproducibility crisis, we’ve discussed the challenges of interoperability – using the wrench as an example, and we’ve talked about making the (meta)data accessible. Has anyone noticed the PRIMARY theme behind all of these?
Yup my favourite METADATA so this post will be rather short since I’ve tackled many of the aspects that I want to highlight already.
First though, if you read through the FAIR principles they say (meta)data – I would challenge anyone to say the principles say that the DATA needs to be accessible, etc… The FAIR principles were created to help the researchers ensure that the data was FAIR by way of the metadata. We all know we cannot share all the data we collect – but as I noted in an earlier post, we should at least be aware of the data through its metadata. Hence my going on and on and on about metadata, or that love letter to yourself, or better yet the data schema!
So let’s talk briefly about Findable. How do we do this? I know you already know the answer – by documenting your data or by building that data schema! The A, I, and R really can’t happen before we fulfill the needs of the Findable 🙂
We already talk about the unique identifier (DOI) in the A in FAIR post. Now let’s take a closer peak at how we can describe our data. Here, at Agri-food Data Canada (ADC), we’ve been developing the Semantic Engine, a suite of tools to help you create your data schema, a suite of tools to help you create rich metadata to describe your data.
Review what the Semantic Engine can do for you by watching this little video
To address the F principles, we just need to create a data schema, or metadata. Sounds simple enough right? The Semantic Engine tools make it easy for you to create this – so try it out at:
https://www.semanticengine.org/
Remember, if you need help reach out to us at adc@uoguelph.ca or by booking an appointment with one of our team members at https://agrifooddatacanada.ca/consultations/
Let’s continue to build knowledge and change the Data Culture by creating FAIR data!
![]()
Entry codes can be very useful to ensure your data is high quality and to catch mistakes that might mess up with your analysis.
For example, you might have taken multiple measurements of two samples (WH10 and WH20) collected during your research.
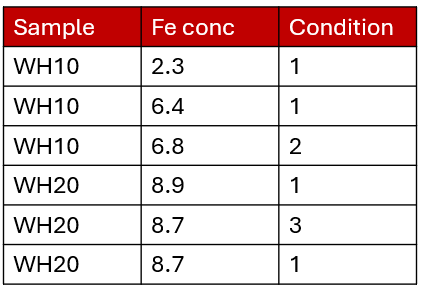
You have a standardized sample name, a measurement (iron concentration) and a condition score for the samples from one to three. You can easily group your analysis into samples because they have consistent names. Incidentally, this is an example of a dataset in a ‘long’ format. Learn more about wide and long formats in our blog post.
The data is clean and ready for analysis, but perhaps in the beginning the data looked more like this, especially if you had multiple people contributing to the data collection:
Sample names and condition scores are inconsistent. You will need to go in and correct the data before you can analyze it (perhaps using a tool such as open refine). Also, if someone else uses your dataset they may not even be aware of the problems, they may not know that the condition score can only have values [1, 2 or 3] and which sample name should be used consistently.
You can help address this problem by documenting this information in a schema using the Semantic Engine with Entry Codes. Look at the figure below to see what entry codes you could use for the data collected.
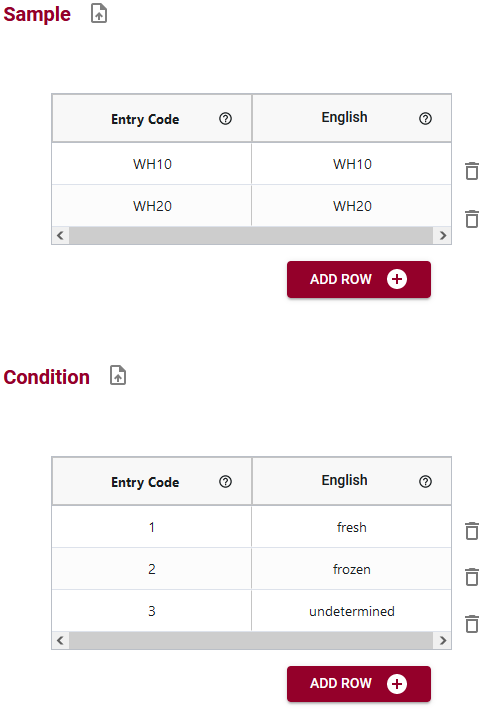
You can see that you have two entry code sets created, one (WH10, WH20) for Sample and one (1, 2, 3) for Condition. It is not always necessary that the labels are different from the entry code itself. Labels become much more important when you are using multiple languages in your schema because it can help with internationalization, or when the label represents some more human understandable concept. In this example we can help understand the Condition codes by providing English labels: 1=fresh sample, 2=frozen sample and 3=unknown condition sample. However, it is very important to note that the entry code (1,2 or 3) and not the label (Fresh, frozen, undetermined) is what appears in the actual dataset.
An example of a complete schema for the above dataset, incorporating entry codes is below:

If you have a long list of entry codes you can even import entry codes in a .csv format or from another schema. For example, you may wish to specify a list of gene names and you can go to a separate database or ontology (or use the unique function in Excel) to extract a list of correct data entry codes.
Entry codes can help you keep your data consistent and accurate, helping to ensure your analysis is correct. You can easily add entry codes when writing your schema using the Semantic Engine.
Written by Carly Huitema