Architecture of OCA Schema Language
Data schemas
Schemas are a type of metadata that provide context to your data, making it more FAIR (Findable, Accessible, Interoperable, and Reusable).
At their core, schemas describe your data, giving data better context. There are several ways to create a schema, ranging from simple to more complex. The simplest approach is to document what each column or field in your dataset represents. This can be done alongside your data, such as in a separate sheet within an Excel spreadsheet, or in a standalone text file, often referred to as a README or data dictionary.
However, schemas written as freeform text for human readers have limitations: they are not standardized and cannot be interpreted by machines. Machine-readable data descriptions offer significant advantages. Consider the difference between searching a library using paper card catalogs versus using a searchable digital database—machine-readable data descriptions bring similar improvements in efficiency and usability.
To enable machine-readability, various schema languages are available, including JSON Schema, JSON-LD, XML Schema, LinkML, Protobuf, RDF, and OCA. Each has unique strengths and use cases, but all allow users to describe their data in a standardized, machine-readable format. Once data is in such a format, it becomes much easier to convert between different schema types, enhancing its interoperability and utility.

Overlays Capture Architecture
The schema language Overlays Capture Architecture or OCA has two unique features which is why it is being used by the Semantic Engine.
- OCA embeds digests (specifically, OCA uses SAIDs)
- OCA is organized by features
Together these contribute to what makes OCA a unique and valuable way to document schemas.
OCA embeds digests
OCA uses digests which are digital fingerprints which can be used to unambiguously identify a schema. As digests are calculated directly from the content they identify this means that if you change the original content, the identifier (digest) also changes. Having a digital fingerprint calculated from the content is important for research reproducibility – it means you can find a digital object and if you have the identifier (digest) you can verify if the content has been changed. We have written a blog post about how digests are calculated and used in OCA.
OCA is organized by features
A schema describes the attributes of a dataset (typically the column headers) for a variety of features. A schema can be very simple and use very few features to describe attributes, but a more detailed schema will describe many features of each attribute.
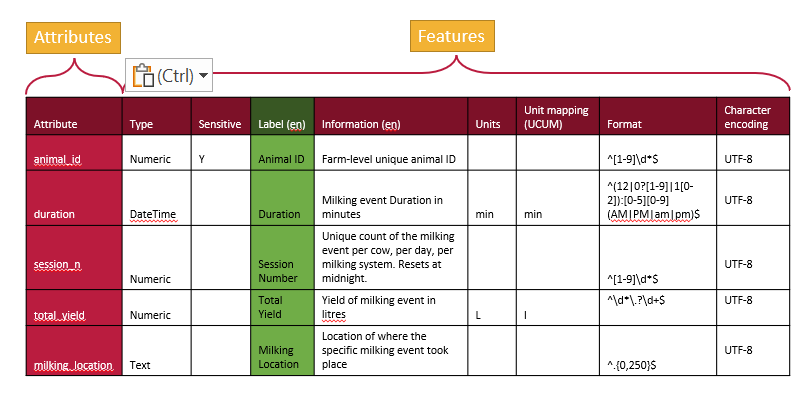
We can represent a schema as a table, with rows for each attribute and a column for each feature.
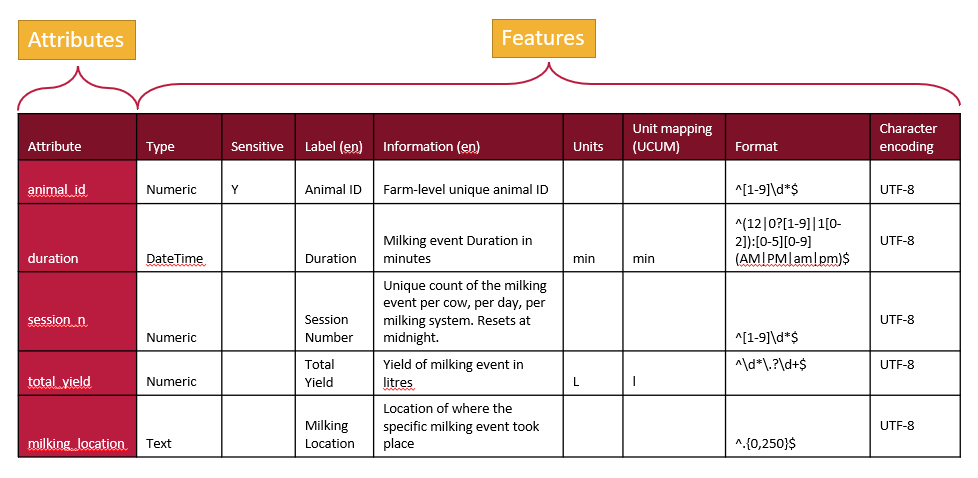
A tabular representation of a schema provides a clear overview of all the attributes and features used to describe a dataset. While schemas may be visualized as tables, they are ultimately saved and stored as text documents. The next step is to translate this tabular information into a structured text format that computers can understand.
From the table, there are two primary approaches to organizing the information in a text document. One method is to write it row by row, documenting an attribute followed by the values for each of its features. This approach, often called attribute-by-attribute documentation, is widely used in schema design such as JSON Schema and LinkML.
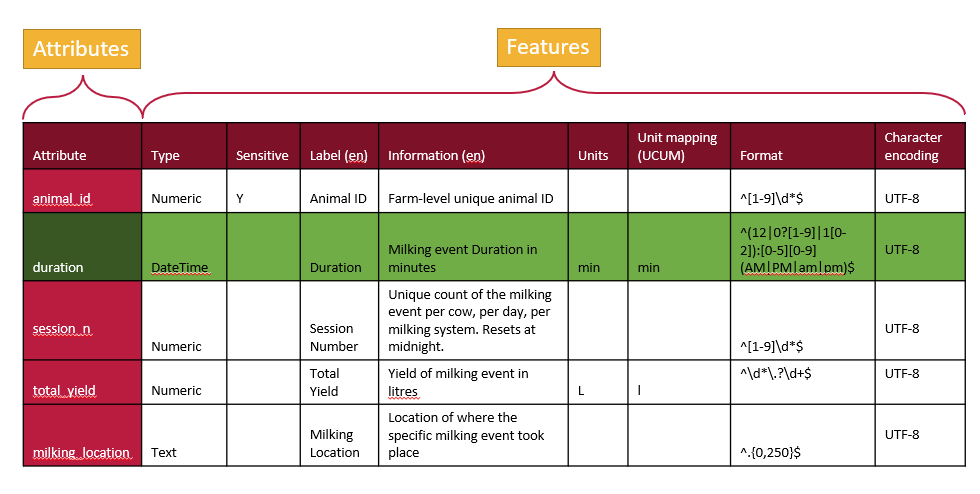
Schemas can also be written column by column, focusing on features instead of attributes. In this feature-by-feature approach (following the table in the figure above), you start by writing out all the data types for each attribute, then specify what is sensitive for each attribute, followed by providing labels, descriptions, and other metadata. These individual features, referred to as overlays in this schema architecture, offer a modular and flexible way to organize schema information. The Overlays Capture Architecture (OCA) is a global open overlay schema language that uses this method, enabling enhanced flexibility and modularity in schema design.
What is important for OCA is each overlay (feature) are given digests (the SAIDs). Each of the columns above is written out and a digest calculated and assigned, one digest for each feature. Then all the parts are put together and the entire schema is given a digest. In this way, all the content of a schema is bound together and it is never ambiguous about what is contained in a schema.
Why schema organization matters
Why does it matter whether schemas are written attribute-by-attribute or feature-by-feature? While we’ll explore this in greater detail in a future blog post, the distinction plays a critical role in calculating digests and managing governance in decentralized ecosystems.
A digest is a unique identifier for a piece of information, allowing it to be governed in a decentralized environment. When ecosystems of researchers and organizations agree on a specific digest (e.g., “version one schema” of an organization with digest xxx), they can agree on the schema’s validity and use.
A feature-by-feature schema architecture is particularly well-suited for governance. It offers flexibility by enabling individual features to be swapped, added, or edited without altering the core content of the data structure. Since the content remains unchanged, the digest also stays the same. This approach not only improves the schema’s adaptability but also enhances both the data’s and the schema’s FAIRness. This modularity ensures that schemas remain effective tools for collaboration and management in dynamic, decentralized ecosystems.
The Semantic Engine
All these details of an OCA schema are taken care of by the Semantic Engine. The Semantic Engine presents a user interface for generating a schema and writes the schema out in the language of OCA; feature by feature. The Semantic Engine calculates all the digests and puts them inside the schema document. It calculates the entire schema digest and it publishes that information when you export the schema. You can view all the digests (SAIDs) calculated for the schema in the readme.txt file.
Written by Carly Huitema