
What is the value of classifying your schema
When you use the Semantic Engine to create a schema, one of the first things you are asked to do is to classify your schema.
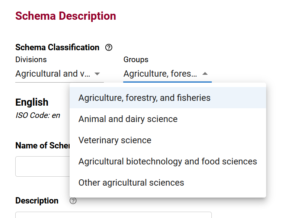
It might seem simple, but as you move further from your domain, what seems like an obvious classification to you may not be so obvious to people outside of your specialty. For example, if someone is talking about a bar there are multiple meanings depending on the context. It could be the location for socialization and drinking, or it could be the exam for lawyers.
With the addition of machine learning and machine assisted searching it is even more important to add important contextual queues to our information to help machines produce more reasonable responses.
A recent publication from the Canadian Federated Research Data Repository (FRDR) demonstrated the challenge they had with automated metadata (e.g. classification) reconciliation. A working group investigated how to build an automated or semi-automated workflow to reconcile metadata keywords from harvested datasets. The majority of their term reconciliation work could not be automated. Ultimately FRDR chose to abandon the assignment of standardized terms to metadata records. The downstream impact means relevant datasets may not appear in relevant searches and research will miss out on opportunities to find and potentially reuse data.
The Semantic Engine supports the findability and categorization of schemas through the addition of schema classifications using the controlled vocabulary of Statistics Canada, specifically the Canadian Research and Development Classification (CRDC) 2020 Version 1.0 – Field of Research (FOR). When you enter your schema classification you are using one of the terms from this controlled list.
Ultimately, by classifying your schema you help ensure that both machines and people can better understand and find your schema and be more confident that they are using it for its intended purpose.
Written by Carly Huitema