A Major Update to the Semantic Engine
Expanding how we model, interpret, and collect complex data
The latest update to the Semantic Engine Schemas tool introduces a set of improvements that push the tool well beyond its earlier focus on simple tabular data. These changes make it easier to describe complex data structures, document real-world datasets more accurately, and even support user interfaces built directly from schemas.
At the same time, some of the updates, especially around recovery and validation, come with important caveats that users should understand to use the tool effectively.
Safer Editing
One of the most noticeable improvements is the addition of automatic, behind-the-scenes storage. As you work, the tool now saves a representation of your schema in your browser’s local storage and can attempt to restore it if your session is interrupted.
This is particularly helpful in situations where:
- A browser tab is accidentally closed
- A session times out
- The page reloads unexpectedly
However, it is critical to understand what this feature is – and what it is not.
This is an emergency recovery mechanism, not a primary workflow.
Browser-based storage can be unreliable. It may be cleared, overwritten, or fail depending on the environment. For that reason:
- You should not rely on recovery as a way of saving work
- You should still complete and download your schema explicitly
- Your workflow should always end with a saved schema file that can be reloaded into the Semantic Engine later
In other words, recovery is a safety net – not a substitute for good versioning and saving practices.
Moving Beyond Tables: Child Schemas
A major conceptual shift in this update is the introduction of child schemas, which allow one schema to reference another.
This change enables schemas to describe nested or hierarchical data structures, rather than being limited to flat tables.
For example, instead of squeezing complex relationships into a single table, you can now model:
- A dataset where one record contains multiple related entries
- Repeating groups of information (such as survey responses or event logs)
- Structured objects that naturally contain sub-objects
However, this added flexibility introduces complexity. In particular:
- Validation becomes more difficult
- Relationships between nested components must be checked
- The existing tabular verification tools are not sufficient for these cases
As a result, working with child schemas may require custom validation approaches or additional tooling. This is an area where the ecosystem around the Semantic Engine will likely continue to evolve.
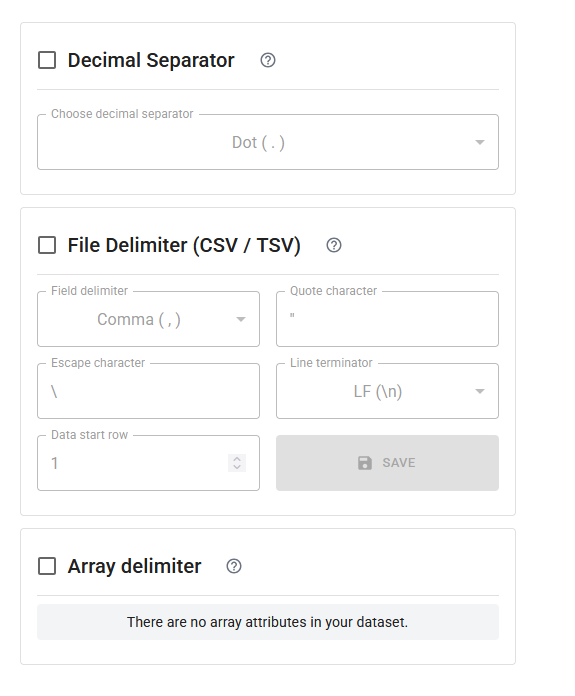
Better Describing Real-World Data: Separator Overlays
Another important improvement addresses a common but often overlooked challenge: data formatting inconsistencies.
In practice, formats like CSV are not as standardized as their name suggests. Different datasets may use:
- Different delimiters (commas, semicolons, tabs)
- Different decimal separators (e.g.,
1.23vs1,23) - Custom separators for arrays within a single field
The updated overlays now allow schema authors to explicitly define these details.
With the new features, you can:
- Specify the delimiter used for arrays in a field
- Define the decimal separator used in numeric values
- Clarify how a dataset structures its rows and columns
This is especially valuable in international contexts. For example, many European datasets use a comma as a decimal separator, which often leads to semicolons being used as column delimiters.
By capturing these details in the schema:
- Humans can more easily understand how to read the data
- Machines can parse datasets more accurately and consistently
- Misinterpretation errors can be significantly reduced
This update reinforces an important idea: a schema should describe not just what data means, but also how it is encoded.
From Data Models to Interfaces: The Form Information Overlay
One of the most forward-looking additions is the Form Information overlay, which allows schemas to describe how data should be collected from users.
In effect, a schema can now double as a blueprint for a form or questionnaire.
Rather than only defining fields and data types, schemas can also include:
- Information about how fields should be presented
- Organizational structure for grouping inputs
- Guidance for building user-facing forms
This does not automatically create forms on its own. Instead, tools must interpret this overlay and render an interface accordingly.
Currently, this is already supported by:
- The Records tool
- The Data Request Tracker (DRT)
This integration is significant because it connects two areas that are often separated:
- Data modeling
- Data collection
By aligning these, the Semantic Engine supports a workflow where a single schema can guide both how data is structured and how it is gathered.
A Step Toward an Integrated Ecosystem
Taken together, these updates represent more than just new features they expand on how the Semantic Engine can be used.
The Schemas tool is evolving into a foundation for a broader ecosystem, where schemas can be:
- Created and iterated safely (with recovery as backup)
- Structured in complex, nested ways
- Used to interpret varied real-world datasets
- Consumed by other tools that handle records and workflows
Some key takeaways from this update include:
- Always finalize and download your schema—recovery is only a fallback
- Use child schemas to model complex data, but be prepared for more advanced validation needs
- Leverage overlays to document data formats clearly and reduce ambiguity
- Explore form overlays to connect schemas with user-facing tools
Final Thoughts
This update marks an important step forward for the Semantic Engine. It expands what schemas can represent, improves how datasets can be described, and begins to bridge the gap between data definition and practical use.