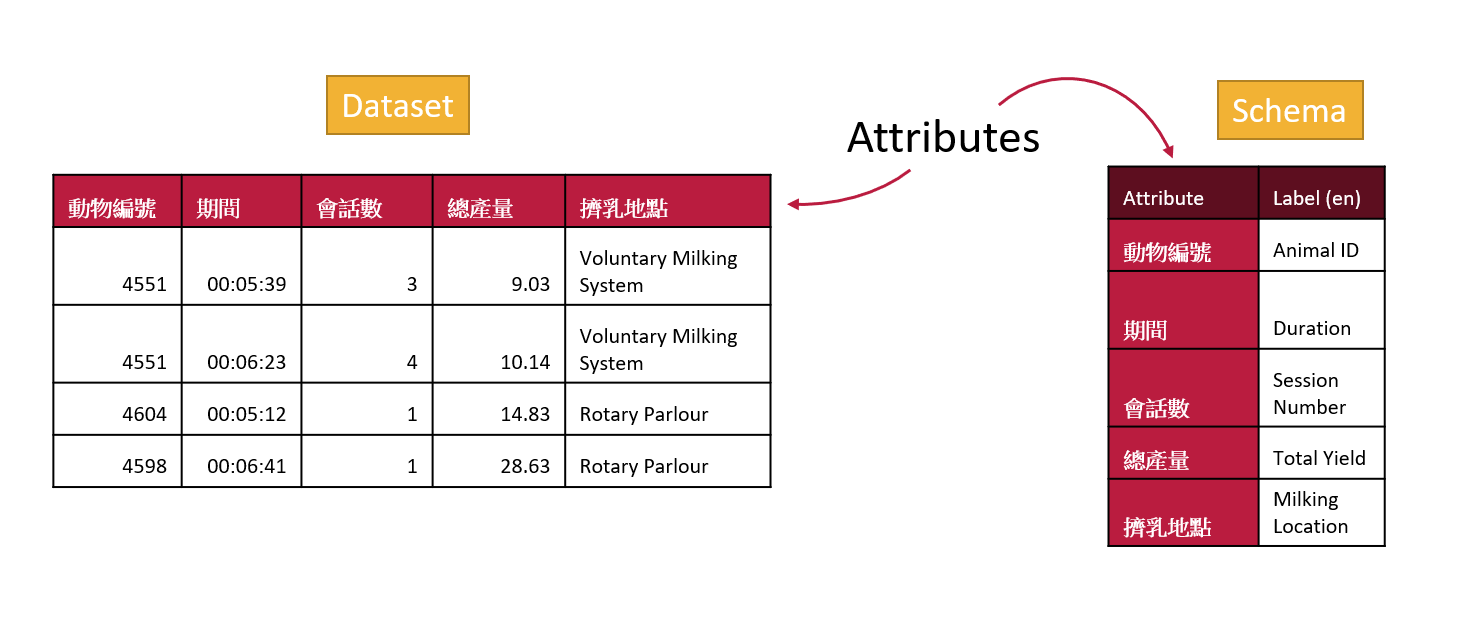
Attributes and labels in OCA
When you document your data schema using the Semantic Engine, you are writing a schema in the schema language of Overlays Capture Architecture (OCA). Let’s do a deeper dive into one of the features of OCA.
Attributes in OCA
When you start using the Semantic Engine, you can either drag and drop your dataset, or you can begin to manually add attributes. Attributes are the names of your columns in your dataset, which should match your variable names in your experiments. In fact, when you drag a dataset into the Semantic Engine, the engine reads the first line of your data, assumes they are your column headers and uses them to create the list of attributes in your schema.

If you are entering your attributes manually, they should be matching the column headers of your dataset.
Labels in OCA
A few screens into the Semantic Engine and you will be asked to add language specific labels. This might be a bit confusing if you’ve already entered in your attributes and you only have one language! The attribute labels and the English language labels might even look exactly the same – and this is OK!
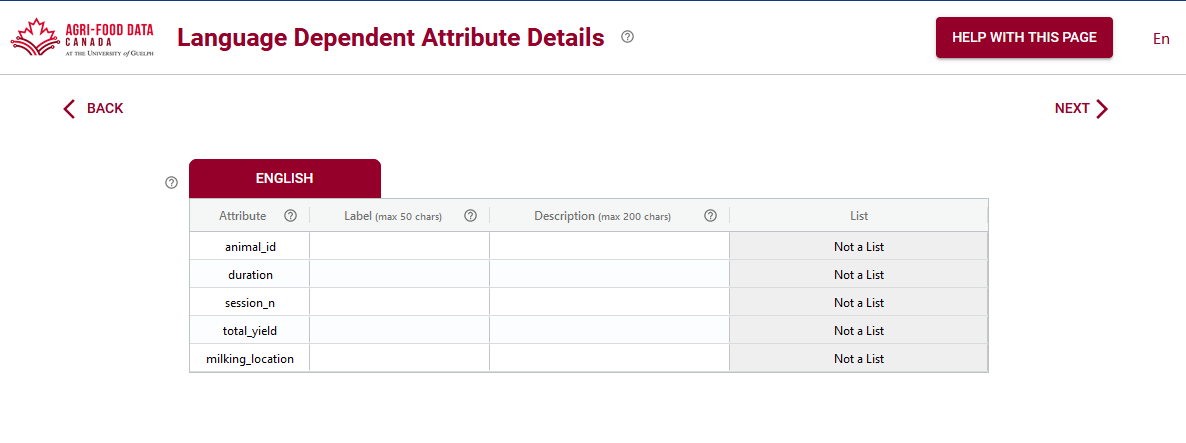
The attributes and their corresponding labels may be the same (or very close), but sometimes they can be very different, especially if the column names are very cryptic. This is your chance to give your data more human readable labels while still preserving the underlying data structure.
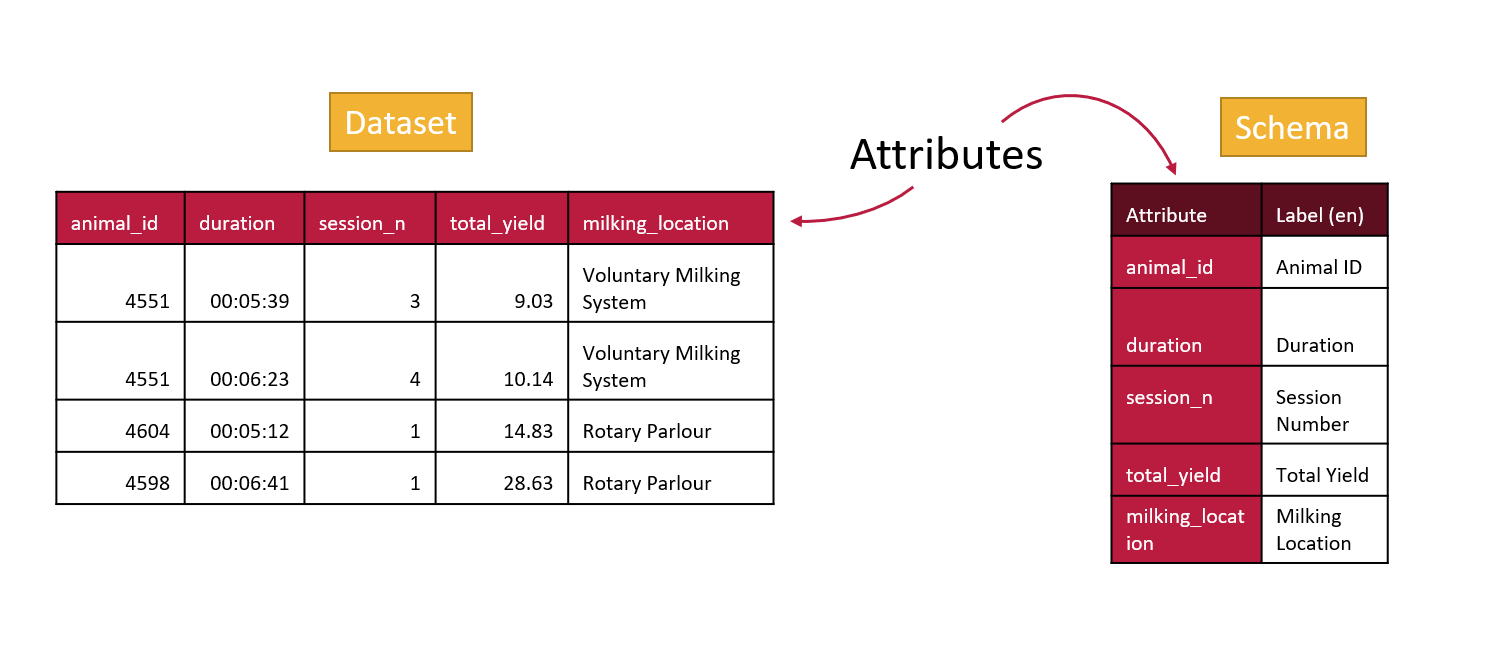
Internationalization with OCA
With labels as well as attributes OCA is able to support internationalization. This means that many people can use the same schemas but they can have helpful information provided to them in their own language.
Your labels may not be very different than your attribute names if they are both in English, but the ability to give labels to attributes will help make your schema more accessible in other languages. All you will need to do is edit your schema in the Semantic Engine and add additional languages.
Written by Carly Huitema